
In our recent Dev Den Office Hours we were asked some very interesting questions. One that caught my attention and on which I elaborated a bit on was the following:
“One question I’ve had a hard time finding info on is in setting up feature branching with multiple environments (dev, test, prod for example) […] I’d love to see a little more of a walk through of how that actually works. Would you have a branch for each environment? Or is there a better way?”
Great question, the important thing to note is that it’s a bit broad.
Software teams are all very diverse. The way you arrange your branching model and the way you sort out your builds can vary tremendously, depending on the type of software project that you’re working on.
The concerns “How do I build my deliverables, my application?” and “How do I manage team work in branches?” can be often seen as orthogonal. You don’t always need to track the state of a specific environment with a branch. I’ll explain this a little bit.
Stash Branching Model
It’s easier to understand things starting from examples so let me give you a high-level view about how the Stash team works. From that, hopefully I’ll be able to distill some guiding principles on how to think about this.
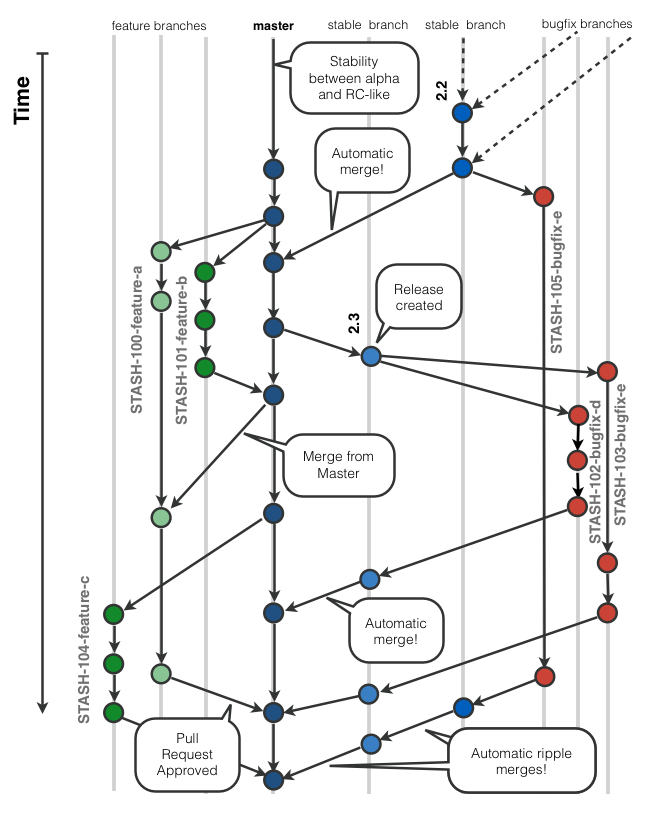
Branching is used to isolate pieces of work like features and bug-fixes, and to make sure that the quality of the stable branches stays high. So the Stash team keeps a master branch semi-stable. Let’s say in a RC-like state (release candidate) generally not production quality, but relatively stable. Feature branches are created off master while bug-fix branches are branched off the maintenance release line they refer to (for example release/3.5 for fixes that will appear in the next 3.5.x maintenance release or master if they target the next official release).
At the end of a release cycle which–in the case of Stash, generally lasts around five weeks–we create a stabilization branch (you might call it a release branch or hardening branch). There we carefully evaluate the security and performance of the application. No new features will be allowed into it anymore. When it’s time, that hardening release branch becomes the final maintenance branch and official builds, tars and zips are created from it for distribution.
For the purpose of this answer I’ll skip the details on how we handle the maintenance branches. Just note that we have some long-running branches and a semi-stable master branch.
Now how does this translate into the deployment pipeline and the build environments?
Stash Build Architecture
See below the build architecture of the Stash project. As you can see, you don’t really need to think about branches when setting up your build environment.
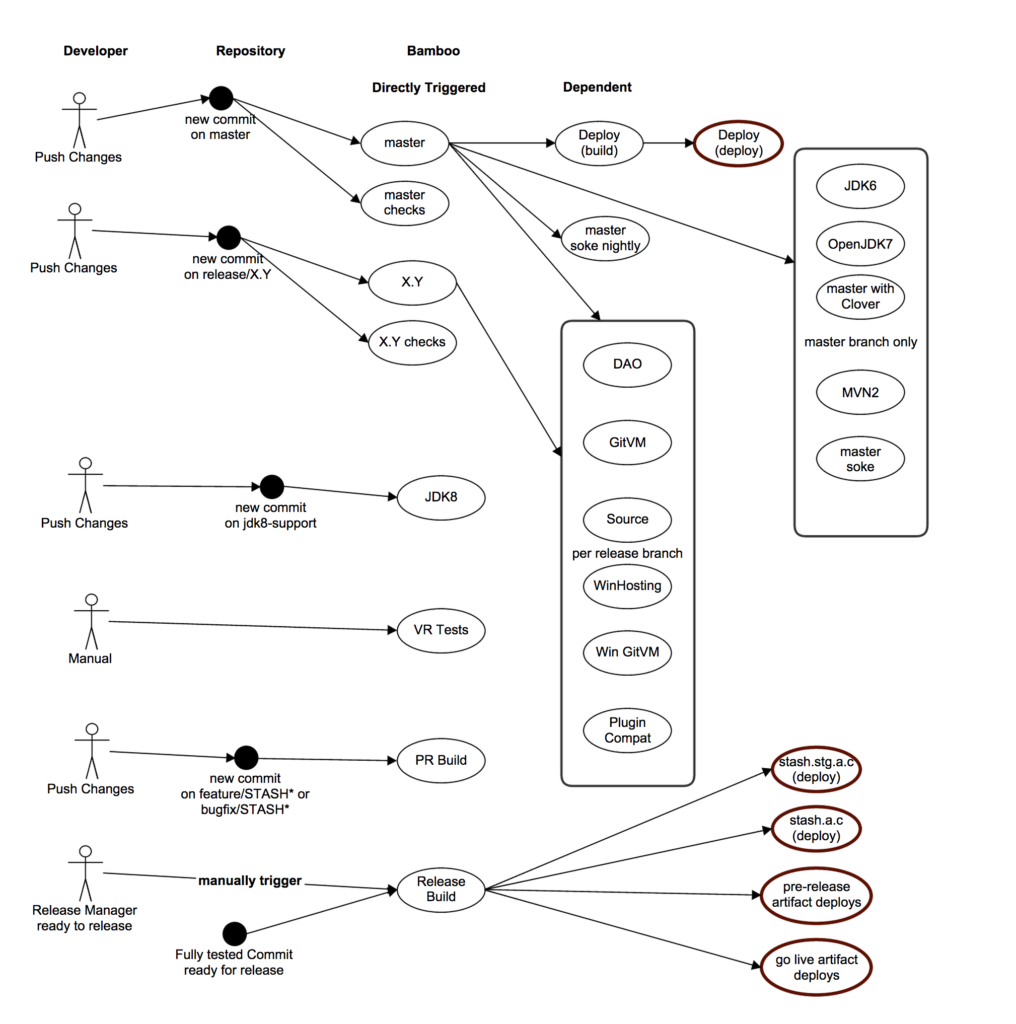
The core part of this whole build infrastructure starts just in a single branch, which is master. Everything is kicked off via a master. Let me walk you through it. Read with me from the top.
Note that we merge to master only completed pieces of work, feature branches or bug-fixes. Those are merged to master once all the tests pass and code review is completed.
Whenever something is pushed to master a build is kicked off right away and separate plans are started to do style checks and coding standard checks, in addition to some other metrics. Some longer, slower parts of the build are off-loaded to other agents.
Because the Stash application is relatively big and complex we have to, for example:
- Perform matrix runs to check the compatibility of Stash with older versions of Git.
- Ensure functionality continues to work across all supported platforms, including various flavours of Linux and Windows.
- Perform a check of all the bundled plugins shipped with Stash.
At the moment all the above plans are triggered by a green master build. The oval that says “master soke nightly” is our heavy performance test.
In addition to the above every time we have a green master build we schedule an automatic deployment onto our first level early access “dog-fooding” server, stash-dev as we call it. This server is used already by some of the teams internally at Atlassian including the Stash team itself.
We also have some other builds kicked off, like builds to check the JDK8 compatibility.
Building Every Pull Request Automatically
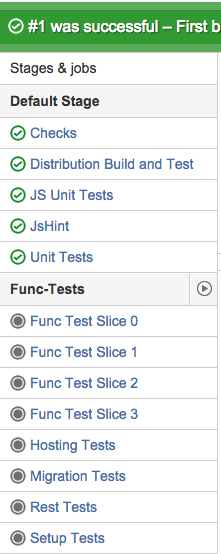
We’re also automatically building every pull request–at least the fast part of the battery of tests. We divide the tests for pull requests into two groups: a “quick” section that includes unit tests and Checkstyle checks that can run really fast and the more extensive functional tests, which take longer to run. The longer, more extensive tests are optional and developers can kick them off by simply pressing the ‘play’ button in the image on the right.
When it’s time to cut an official release we have a Bamboo build that automates a large part of our release process. It creates the distribution, generates the documentation, uploads the documentation to developer.atlassian.com, uploads the release artifacts, etc. It’s highly automated – although there are still a few manual steps.
The second level of “dog-fooding” happens at this time. Before we deliver a new release to the general public, we want to make sure to expose it to a wider internal Atlassian usage. For this we have stash.atlassian.com. Deployments to this server are also now mostly automatic.
Conclusions
This long explanation was to send one major point across: branching model and build pipelines don’t necessarily have to be paired together in complex ways. How do you guys organize branches and deployment pipelines? Comment here or tweet at me @durdn and or @atlassiandev.