
Video conferencing systems are complex. They have evolved over the decades, along with hardware and software, to be much more accessible and affordable. But they are still complex and will remain to be so. In this post we will introduce our approach to one of the important problems – that of scaling the number of participants – and show how our solution also helps us to provide a better user experience.
For those who don’t know us yet, we're the Jitsi team, and we're new to Atlassian. We specialize in real-time communication and now, as a part of Atlassian, we'll be adding our expertise in multi-user video conferencing to make HipChat better than ever.
Video conferencing 101
One-to-one video calls are ubiquitous – they're everywhere. After the IETF figured out proper NAT traversal, setting up a 1:1 call became simple. You can make a 1:1 call from your cellphone, tablet, or from any laptop. Add more people to the mix, now that's when it gets trickier.
You can accomplish three-way calls without any server infrastructure, by using a full mesh topology (i.e., connecting everyone to everyone else).
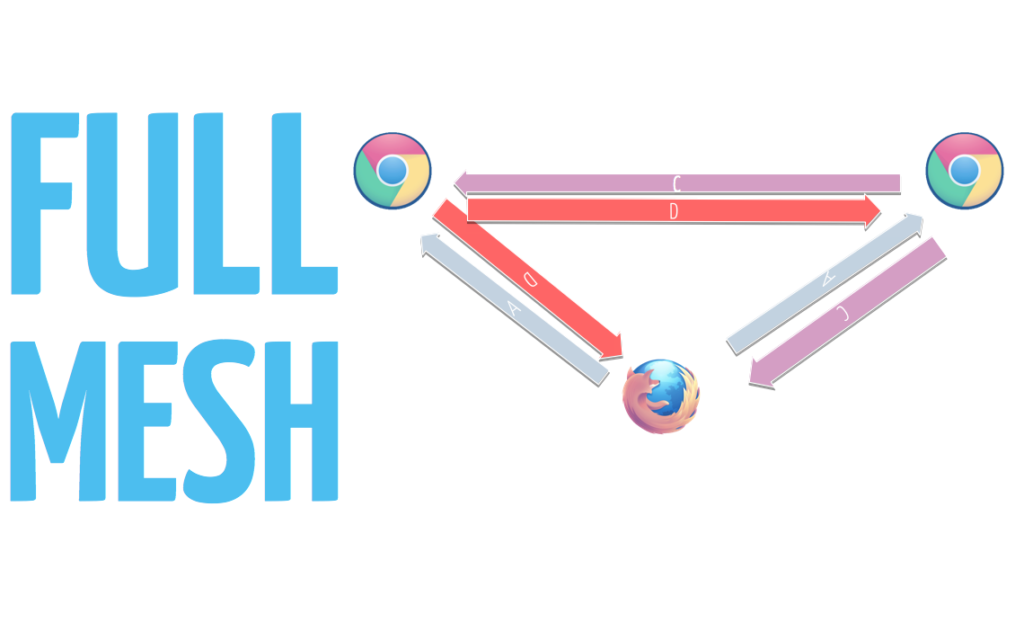
Beyond three people, this is where it gets complicated. You can safely say that full-mesh just doesn’t scale.

To extend beyond four participants you need a server component. The participants and the server connect in a star topology, with the server at its center. People use two main groups of server components:
Multipoint Control Units (MCUs)
These are server components which process the multimedia coming from clients. Usually they mix audio, create a composite video, and send a single “mix” stream to each client. The media processing makes them very expensive in terms of CPU, but allows for somewhat simpler client software.
Selective Forwarding Units (SFUs)
SFUs act like routers, just forwarding packets without media processing. This allows for very CPU efficient implementations, but the network resources that they need are generally higher.
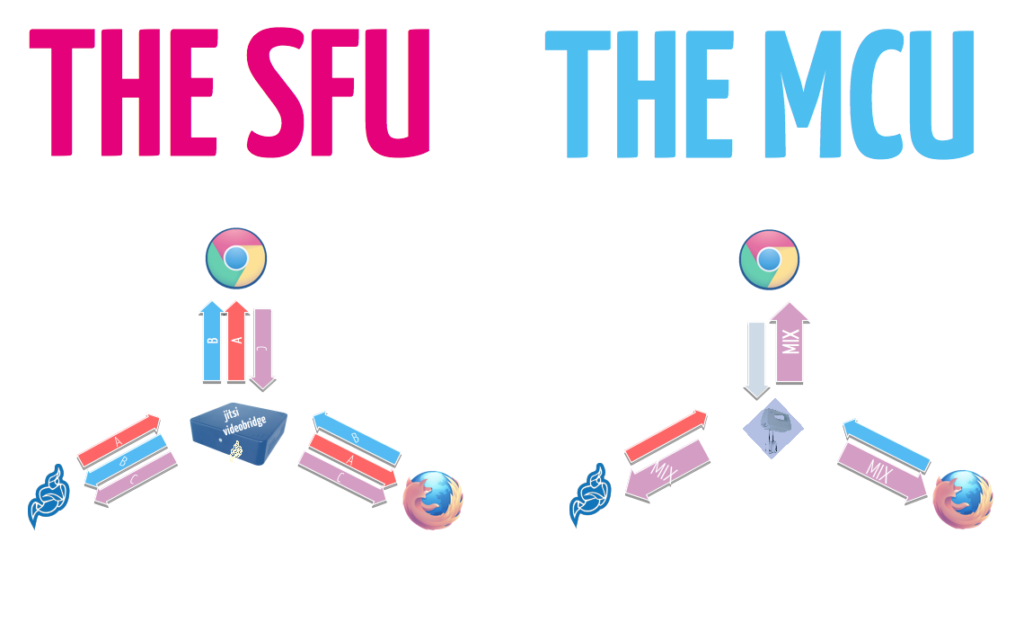
In the most simplistic case an SFU forwards everything, without any selectivity. This means that the number of streams it forwards (and thus the amount of bandwidth needed) grows as the square of the number of participants: three participants, 3×2=6 streams; ten participants, 10×9=90 streams. This scales up to around 10-15 participants and then breaks apart. With no selectivity, an SFU is just an FU.
Last-n
Our server component is called Jitsi Videobridge. It’s an SFU and it’s quite CPU efficient. Most CPU cycles are used for encryption/decryption of RTP (media) packets, so the CPU usage is proportional to the bitrate (see Jitsi Videobridge Performance Evaluation for more details). So if we solve the bandwidth problem for a big conference, we also solve the server CPU problem.
One of the ways we use selectivity to solve the scaling problem is with what we call last-n. The idea is that we select a subset of n participants, whose video to show, and we stop the video from others. We dynamically and automatically adjust the set of participants that we show according to who speaks – effectively we only show video for the last n people to have spoken.
How does that help with the scaling problem? The number of streams that we forward (and so the amount of traffic we generate) grows linearly:
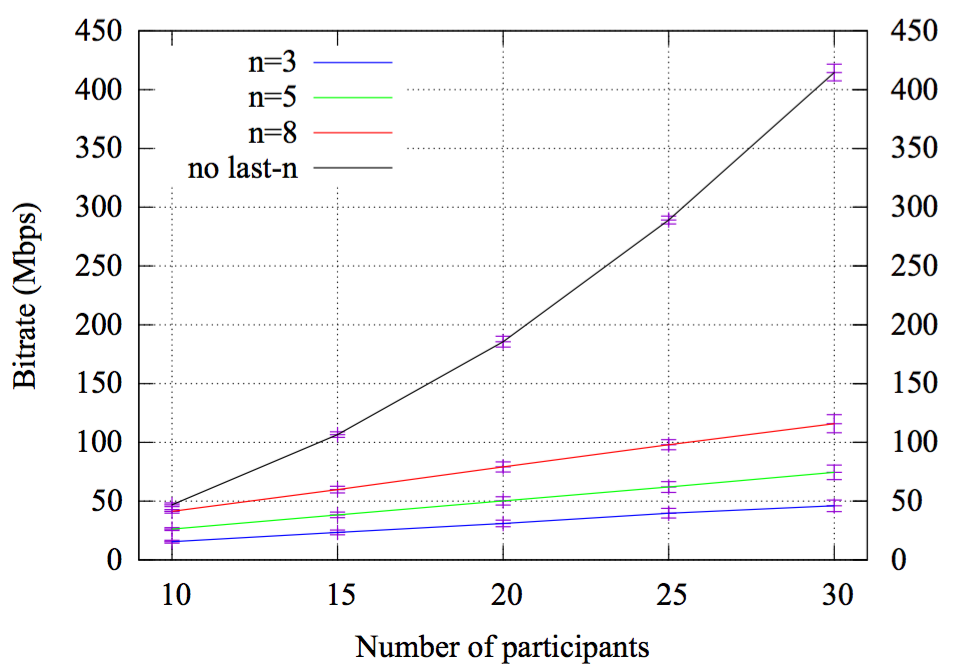
What does this mean? By using the same server resources you can have either:
-
Conferences with more participants.
-
More conferences.
And what about the clients, the UI, and UX?
-
Less network resources – fewer streams are received.
-
Less CPU resources – fewer streams are decoded.
-
Less clutter – fewer video elements in the UI.
-
Requires no interaction – when someone speaks, we show their video automatically.
In most conferences only a few of the participants actively talk. With last-n we take advantage of this, but still allow everyone to participate.
One difficult thing with last-n is figuring out who to show. This is referred to as Dominant Speaker Identification and it’s a tricky problem. For us, it's additionally complicated, because we need to do it on the SFU – without decoding the audio streams.
You can find out more about last-n in a paper which we recently published: Last N: Relevance-Based Selectivity for Forwarding Video in Multimedia Conferences
If you want to see last-n in action, you can head over to our testing installation here: http://beta.meet.jit.si/
Note that we have set n=5 there, so you will need at least seven people before you see the effects of last-n. Also note that this is just a testing environment and might not be very stable.
So, that's a basic breakdown of what the Jitsi Team has been up to. We're very excited to be a part of Atlassian and we're looking forward to all of the progress our two teams can create together.