
As we announced a little while ago, Atlassian is collaborating with GitHub and many others in the community to contribute to the ongoing development of Git LFS. Together, we’re trying to solve the problems that face teams who need to store large files in their Git repositories, on projects like game development, media production and graphic design.
Our own Bitbucket Server and SourceTree provide professional teams with the ultimate Git solutions, including support for Git LFS.
Last week, Git LFS reached a new milestone with the release of version 1.2. Looking at it now I think we’re all surprised how many things we squeezed in! I thought I’d take a moment in this blog post to highlight one of the features of this release, but if you’re using Git LFS I recommend taking a look at the full release notes (in which I’m ‘@sinbad‘ 🙂 ) .
Cloning at light speed with git lfs clone
A new feature you definitely want to take advantage of if you have a very large repository, and especially if you’re on Windows, is the specialized LFS clone command:
git lfs clone ssh://git@mybb-server.com:7999/lfs/repo.git my-clone
The git lfs clone command operates exactly like git clone and takes all the same arguments, but has one important difference: it’s a lot faster! Depending on the number of files you have it can be more than 10x faster in fact.
How? What is this sorcery?
The difference is all about how exactly LFS content is detected and downloaded when you clone a repository. In Git LFS, large file content is stored separately from the Git repository, and only small pointers are committed in their place. In order to give you a valid working copy to edit, some process has to turn those pointers into real file content, downloading it if necessary. This task is usually done by something called the smudge filter, which is called whenever you check something out into your working copy.
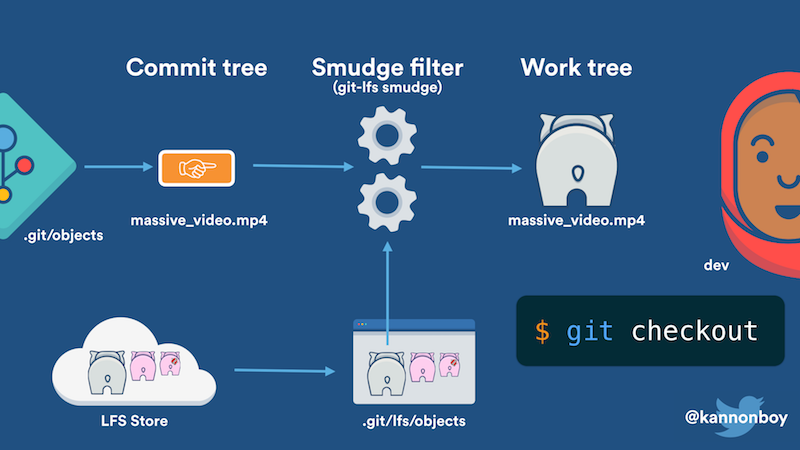
So under normal circumstances when you use git clone, firstly git downloads the repository objects, which in LFS terms are just pointer data. Once that’s done, the default branch is checked out to create your starting working copy, and the smudge filter is called for any LFS files. This then downloads any content it doesn’t have on demand.
So far, so good. The problem is, Git calls the smudge filter separately for every LFS file it encounters, and unfortunately this doesn’t perform very well, for several reasons:
- Git LFS usually makes batch calls to the server’s LFS API, asking about multiple files at once. But since the smudge filter only asks for one file at a time, it generates a lot more API calls.
- After hearing back from the API, Git LFS usually downloads multiple files in parallel, but can’t in this case.
- A separate Git LFS process is forked via the smudge filter for each file checked out. This is especially expensive on Windows where there is a significant performance cost for starting new processes.
How ‘git lfs clone’ fixes this
We tried out a number of approaches, and the eventual solution we settled on for 1.2 was very much a group effort; it even resulted in a patch to Git core which makes the feature even faster when used with the recently released Git 2.8.
Step 1: it calls ‘git clone’ with custom settings
The new git lfs clone command first calls git clone, but it disables the LFS smudge filter using Git’s -c option; like this:
git -c filter.lfs.smudge= -c filter.lfs.required=false clone <url> <path>
Depending on the version of Git you’re using, this command will be slightly different to cope with the way Git behaviour has changed. Git 2.8+ is the most optimal case.
This means that when it comes to the checkout part of the clone operation and files which are tracked in Git LFS are created in the working copy, the smudge filter is not invoked and they are initially written to disk exactly as Git sees them; just pointer files that look something like this:
version https://git-lfs.github.com/spec/v1
oid sha256:d7c37164a1ab1ceff70e2d73addd6c554a737ef072fc4ec4efed120537274ca3
size 21743
Step 2: it calls ‘git lfs pull’ to bulk download
Once the clone is complete, git lfs clone moves on to the second step, which is to perform the same tasks as git lfs pull to download and populate your working copy with real LFS content. This is in itself a compound operation which does the following:
- Runs the equivalent of
git lfs fetchto download the LFS content you need. - Performs
git lfs checkoutto replace LFS pointer files in your working copy with real content.
In Git LFS the concept of fetching is the same as core Git; downloading the content you need but without changing the working copy. Because this is done in bulk when using git lfs clone, fewer calls are made to the LFS API and multiple files are downloaded in parallel, making this much faster than the per-file smudge approach.
Normally the fetch operation will only download LFS content you need for your current checkout. However if you have configured Git LFS to fetch ‘recent’ content, this will also download other content to make it faster to switch to recent branches or commits subsequently. Run
git lfs help fetchand see the “Recent changes” section for more information.
More to come
In future we’ll look at whether we can gain similar performance benefits in scenarios other than clone, where reliance on the smudge filter could slow things down, such as pulling Git changes and switching branches. Clone is by far the most expensive case though so it made sense to tackle this one first.
We’ll be updating SourceTree to take advantage of this faster clone route soon too, so you won’t have to do anything special to benefit from it.
Conclusion
I hope you’ve found this interesting! I highly recommend you check out the new release of Git LFS, and we on the team look forward to bringing you even more useful features in future.