
This post is the third part of a series on how we built Bitbucket Data Center to scale. Check out the entire series here
SCM cache
As we saw in parts one and two of this series, build agents are notorious for generating “storms” of git clone and fetch operations: One push can sometimes trigger many builds, each consisting of many parallel stages, so the same repository can end up being cloned very many times in quick succession. The repetitiveness and relatively high cost of these clones makes them perfect candidates for caching.
Ever since version 1.2, this is exactly what we’ve done.
Whenever Bitbucket receives a git hosting request, we generally spawn a git process and hand it off to that. But that’s not all we do. We also “listen in” on the connection, decoding all the exchanges between the git server and client at the packfile transfer protocol level. If Bitbucket determines that the request is a clone and potentially cachable, then while streaming the generated pack back to the client we also save a byte-for-byte copy of it to a file on the cluster node’s fast local storage. The next time an identical clone request is received for the same repository, we can simply stream the same pack, byte-for-byte, back to the client from the cached file, without even having to start a git process.
The part of Bitbucket that does all this is called the _Source Code Management cache_, or SCM cache for short. The SCM cache saves a lot of CPU and memory in a typical Bitbucket instance, allowing it to handle a much greater load of clone operations on the same hardware. Under typical workloads, the SCM cache is highly effective. On our own production instance, the hit rate is generally as high as 80%.
|  | When a clone or fetch is received:
When a push is received:
|
SCM cache in a Nutshell
The introduction of the SCM cache has another interesting benefit, even when it misses. On a cache miss, the cache serves as a buffer between the server git process and the client, effectively decoupling the two. The server git process output can write the packfile to the cache as quickly as it likes, without having to wait for the client to read all the data over the network. Meanwhile, the client request is being served out of the cache, and can take as long as it likes without holding up the git process on the server. This decoupling allows the server process to finish and release the memory to the operating system much more quickly, greatly reducing memory consumption overall.
SCM cache is especially beneficial in a clustered Data Center instance where all the repository data is stored on a shared NFS volume. The caches are stored on a fast local disk on the cluster node. A cache hit replaces the network I/O required for generating the pack data with local I/O for reading from the cache, thereby reducing the demand on the NFS server and network bandwidth.
The graphs below show how the introduction of the cache affects the CPU and memory usage on the server for clones. All scenarios (use the selector to choose one to display) clone a 250 MByte repository over a 15 Mbit DSL connection. The limited bandwidth means that the git process on the server frequently has to wait for the remote client to read data before it can continue.
<div id="bbs-stash-cache-miss-panel" class="graphPanel">
<div class="cpu"><span class="graphTitle">CPU usage for the git and Bitbucket processes</span><svg></svg></div></div>
<div id="bbs-stash-cache-hit-panel" class="graphPanel">
<div class="cpu"><span class="graphTitle">CPU usage for the git and Bitbucket processes</span><svg></svg></div></div>In the “no cache” scenario, the git process on the server stays alive until the client has received all of the requested data (just under 140 s) and consumes CPU and memory during this whole time. In the “cache miss” scenario, the git process on the server streams its output directly to the cache and can finish much more quickly (after about 20 s). It then takes another 120 s for the pack to be sent to the remote client, but during this time there is no git process on the server consuming CPU and memory.
The total git CPU time is about the same in the “cache miss” and “no cache” scenario, but in the “cache miss” scenario it is compressed in a much shorter time window (20 s instead of 140 s). Looking at memory consumption, the “cache miss” scenario is much better; the git process still consumes up to 700 MBytes, but releases the memory much more quickly, freeing up resources for other processes.
The “cache hit” scenario is the absolute winner: it consumes minimal CPU and memory because git does not have to compute the pack at all; it can simply be streamed from the cache.
In recent versions (4.10 and 4.11) we’ve made further improvements to the cache eviction mechanism to ensure that “hot” repositories remain in the cache longer. When the disk cache starts getting full, caches that have not been accessed for a long time are the first to be cleared. This further increases the cache hit ratio and effectiveness of the cache.
Loose coupling
While we’ve focused a lot of attention on Git hosting load, that doesn’t mean we’ve ignored performance and scale across the rest of Bitbucket. We’ve also spent a ton of effort making sure Bitbucket Data Center scales not only git operations, but all kinds of operations horizontally across large clusters.
First of all, a bit of history on the development of Bitbucket Data Center. Since the beginning, Bitbucket Data Center has used Hazelcast internally to distribute many of its subsystems across the cluster. Using Hazelcast let us build “cluster awareness” relatively easily into every subsystem that needed it, and tune all our various clustered data structures for the best balance of consistency, availability, and tolerance of network conditions.
As we’ve deployed Bitbucket Data Center to greater and greater scale,
though, we’ve increasingly found it preferable to minimize the
dependence of cluster nodes on each other wherever possible. The
clustered data structures provided by Hazelcast are convenient for
sharing data across multiple cluster nodes, but they can sometimes come at a cost: “tight coupling” between nodes and occasional delays where one node has to wait for another to respond. In Bitbucket, contention between cluster nodes on the same data is actually quite rare, so it makes a lot of sense for us to use more “loose coupling” between nodes and “optimistic” concurrency control strategies wherever possible.
Loose coupling not only reduces the network traffic between nodes and improves performance, but is generally good for the health especially of large clusters, as any delays on one node (for example, due to network issues, OS issues, or GC pauses in the JVM) can’t affect request or other processing on other nodes in the cluster.
An example of where we’ve evolved towards looser coupling is in our Hibernate second level (L2) cache implementation. This cache accelerates all Bitbucket’s accesses to database records and queries, and must be kept both transaction aware and consistent across the cluster.
Our Hibernate L2 cache implementation is provided by Hazelcast, and can be configured in two modes: DISTRIBUTED and LOCAL. DISTRIBUTED mode pools the memory of all cluster nodes to provide a very large cache, but does mean that some cache accesses may need to communicate with another cluster node to get or put the data they need. LOCAL mode allows each node to manage its own memory and cache records and queries independently, with node-to-node communication only needed for invalidating entries to maintain consistency.
We spent quite some time optimizing and stress testing both DISTRIBUTED and LOCAL mode cache providers (which incidentally we also contributed back to Hazelcast), and for us LOCAL mode was the clear winner. Now, all our Hibernate L2 caches are configured in LOCAL mode by default.
The effect on communication between cluster nodes when we rolled this change out on one of our internal instances (shown by the red arrow) was dramatic:

LOCAL mode caches also give significantly better overall throughput and response times, especially in large clusters. This controlled E3 experiment (called loose-coupling.json) shows the improvement with a typical workload mix against a couple of different cluster sizes configured in LOCAL and DISTRIBUTED modes:
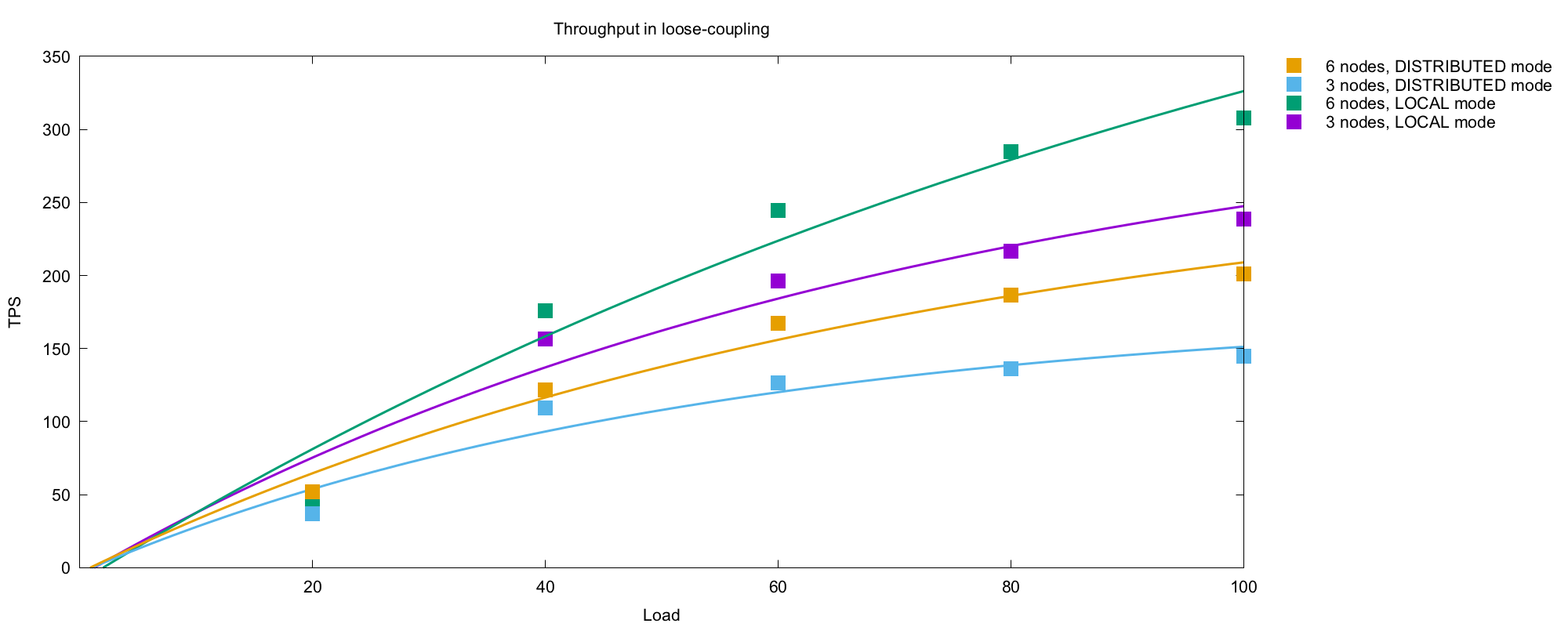
The Hibernate L2 cache is one example, but there have been a host of other areas where we’ve optimized Bitbucket for looser coupling across all our subsystems in recent releases. Our background job scheduler (which used to be implemented using Quartz, but now uses Atlassian Caesium), key parts of Bitbucket’s pull request, comment drift and SCM cache algorithms, and a range of other caches across Bitbucket core and applications have all been optimized for loose coupling in a similar way.
Conclusion
The result: for both Git hosting load and general interactive load with tens of thousands of users, we’ve put in a ton of effort to make the latest release of Bitbucket Data Center (4.11 at the time of writing) the most performant and scalable Bitbucket yet.
And with the E3 tool now public anyone in principle can run the same performance tests that the Bitbucket development team uses, and see the performance improvements for themselves.