
*Currently, users can enjoy these changes only in Jira Server and DC.
We are excited to share a preview of upcoming performance improvements to agile boards in Jira Software 8.0. This post will share the details of how we’ve been able to make progress in this area, performance testing that we used to quantify the results, and other specific technical changes.
We hope that these details will inspire you in any performance-related work you may be taking on, or illustrate creative solutions to build performant Jira apps and customizations in the future.
We know that teams sometimes struggle with agile boards, since large boards can be very slow on initial loading. That's why we've taken on the challenge of making boards and backlogs load faster for as many Jira users as possible.
Splitting up the backlog
How many issues do your teams use for their planning? It could be over a hundred issues for a week or two-week-long sprints. However, by default, Jira will attempt to load all issues in a backlog or kanplan view, which is much more data than is actually necessary at first glance. To save the time that is sometimes spent rendering of issues, we implemented a split in backlogs and kanplans.
With this change, users don't need to wait for every issue to render on a backlog. They'll only see 100 or 500 from their backlog issue list upon first load (depending on their configuration). What if a user wants to see them all? They’ll just click the "Show all issues" button.
Manipulations with DOM are the most time-consuming operations when a page loads for the first time, so rendering only 100 issues instead of up to 10,000 decreases the time spent on loading several times.
For most comfortable use, depending on backlog configuration, users will see 90 or 490 issues at the top of the issue list as the representation of the most important tasks, a button to show all issues and 10 issues at the bottom of the backlog. The "Show all issues" button will tell the number of issues hidden by the split.
Updated CSS layout
Now we use more of the CSS flexbox, and we’ve fixed several bugs and additional reflows on boards and backlogs that were caused by using JavaScript.
As a simple example, we used JavaScript to truncate long project keys on issue cards for boards if there was not enough space to display the full issue key. The reasoning behind this was to make sure that the issue number was as visible as possible, since it is a more useful piece of information than the project key.
We achieved the same CSS-based behavior by splitting the issue key into 2 blocks and using flex shrinking and text-overflow ellipsis.
.ghx-key-link-project-key {
flex: 1 1 auto;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
.ghx-key-link-issue-num {
flex: 1 0 auto;
}
Another challenge was configuration the priority of changing the size of DOM elements. That's why we used flex-shrinking:1 for project key and flex-shrinking:0 for issue number. With this, we could make the project key change its size without touching the issue number.
This solution works much faster than its JS alternative, which calculated available sizes and changed strings to update DOM elements for each issue on the page. As a bonus, users will get the correct issue key value while attempt to copy it now.
Fewer performance-taxing libraries
We also solved some issues with libraries performing taxing operations in DOM, and refactored some code to avoid these operations. Now we only use the required limit for this functionality.
The most common example is using skate.js library working with DOM nodes that can potentially grow. Because of how specific Plan Mode looks, there are tones of DOM nodes representing issue information. Observing of them with skate.js caused huge performance problems that increased with the amount of data shown on page.
To reduce this impact we removed epics, versions, and issues lists from the skate.js context using data-skate-ignore attribute and refactored some functionality such as the inline issue create, to make it work again, but not to depend on this library.
Decreased backlog issues list response size
Previously, each issue in the API response for issues list for backlog looked like this:
{
issues: [
{
id: 906874
key: "SP-1087"
linkedPagesCount: 5
assignee: "admin"
epic: "SP-196"
epicField: {
canRemoveEpic: true
editable: false
epicColor: "ghx-label-2"
epicKey: "SP-196"
id: "customfield_10002"
label: "Epic"
renderer: "epiclink"
text: "Really big task"
}
estimateStatistic: {
statFieldId: "customfield_10006",
statFieldValue: {}
}
status: {
description: "This issue is no longer not done."
iconUrl: "http://url"
id: "10001"
name: "Done"
statusCategory: {id: "3", key: "done", colorName: "green"}
}
statusId: "10001"
statusName: "Done"
statusUrl: "http://url"
summary: "Some description here"
typeId: "10100"
typeName: "Task"
typeUrl: "http://url"
...
}
...
]
}As you can see from the example, each issue contained a duplicate of the full data set about the epic, status, or type it belonged to. At the same time there were epic and version lists in the same response. It means we had tons of duplicated info inside each issue.
When 8.0 arrives, it will be dramatically consolidated. We refactored the response structure of getting issues list for backlog to normalize information and get rid of duplicates. Now, only the necessary data for issue list rendering is left, like in this example:
{
issues: [
{
id: 10000
key: "TEST-1"
done: false
epic: "TEST-24"
epicId: "10023"
estimateStatistic: {
statFieldId: "customfield_10006"
statFieldValue: {
text: "2"
value: 2
}
}
estimateStatisticRequired: false
fixVersions: [10001]
priorityId: "3"
projectId: 10000
statusId: "10000"
summary: "Issue summary"
typeId: "10001"
...
}
...
]
...
entityData: {
epics: {
10023: {
epicField: {
id: "customfield_10003"
text: "Epic 1"
epicColor: "ghx-label-1"
epicKey: "TEST-24"
...
}
}
}
priorities: {
3: {
priorityName: "Medium"
priorityUrl: "http://url/jira/images/icons/priorities/medium.svg"
}
}
statuses: {
3: {
status: {
id: "3"
name: "In progress"
...
}
statusName: "In Progress"
statusUrl: "http://url/jira/images/icons/statuses/inprogress.png"
}
...
}
types: {
10001: {
typeName: "Story"
typeUrl: "http://url/jira/images/icons/issuetypes/story.svg"
}
}
hasBulkChangePermission: true
}
}An issue contains only the data about IDs for epic, type, etc., and the corresponding data needed for rendering issues list is stored only once for the whole response.
We did a separation to fetch full epics and versions data from other corresponding API endpoints.
With this change, the response size is reduced by 20%. For large boards and slow internet connections, this is the best way to organize data. As a bonus, user doesn't have to wait to start working with issue lists while epics and versions are still loading.
The approximate size for 10,000 issues is now 535KB gzipped (4.5MB raw)instead of 685KB gzipped (10.2MB raw).
This change removes some additional memory pressure from the backend, since it doesn't have to hold a 10MB-large JSON while it is transferring to the client, and it takes less time to compute it.
Refactoring panels
Refactoring was also applied to epics and versions panels on the backlog page.
Now, if users aren’t going to use them, they don't have to wait for the panels to render. We have postponed fetching data and rendering these panels up to the moment they are open.
In addition to separate endpoints for retrieving epics and versions data, we fixed the HTML structure not to render unnecessary elements and duplications.
The changes have been applied to these areas:
- expanded area of a particular version or epic issue, when it is currently closed it is not rendered anymore until is is really expanded
- HTML of epic edition popup is now removed from each epic and appears only when it is called
It saves around 60 rows of HTML on the page for each epic on the panel and 35 rows for each version. Now your browser can really breathe easily!
One more change connected to the epics panel is the number of linked Confluence pages, shown in the epic's description. Calculating these links exerted pressure on the backend and slowed the page down, as Jira needed to go through each epic issue and execute a search for pages for each connected Confluence instance only to show this number. That is why, for performance reasons, this number was removed from the button. Nevertheless, users can still see all the linked pages clicking on the "Linked issues" button.
Days in column
This feature is mostly used for Kanban boards. For each issue on the board, Jira performed a complex calculation based on the issue transition history that checks the number of days an issue spent in a particular column. Such operations cost 26% of the time needed to generate a response. Since this calculation is too expensive, this feature is now switched off by default for new boards. Board admins still can enable it in the board settings.
Additionally, we've added a global setting to turn this feature off for the whole instance. It is available for Jira admins in Jira Software Configuration for the case of performance degradation. Turning it off, for instance, wouldn't give board admins ability to enable it back in board settings. However, if an admin decides to enable it back – the previous state of this feature would be restored for every board.
Context changes
We are in progress of making pages weigh less. In Jira 8.0 we separated the "gh-rapid" context into 4 independent ones:
- gh-rapid-plan
- gh-rapid-work
- gh-rapid-report
- gh-rapid-detailsview
This change results in loading only the necessary data for your page without overloading it with CSS and JavaScript files that are not used. It also makes an impact on some plugins and helps with initial page loading time.
Early data fetching
There are a very large amount of scripts executing to make Jira work.
Before Jira 8.0, the list of issues to display was the last thing the client tried to fetch. Sending this request was postponed by other script executions (after the HTML/CSS/JS parsing and practically all other XHR requests for context). At the same time, it has the most potential to take a long time for Jira to generate and return the result. This shouldn’t be done synchronously.
Since our web script code download/parse/execute stage is long enough, an early ajax data fetch is a helpful way to speed up the page loading process.
While the backend is generating the response, Jira can parse and execute all other scripts and prepare a page for data parsing and rendering.
Measuring performance progress
We announced a public beta of Jira Performance Tests (JPT), the framework that helps the Jira team to benchmark the performance of each Jira version to avoid regressions over time. Follow go.atlassian.com/jpt to learn more about it.
Results speak louder than words – what was the outcome?
All of the optimizations listed above helped to decrease time of the initial page load for Jira agile boards by:
| Type | Before Jira 8.0 | After Jira 8.0 |
| Big backlog (10 000 issues) | 85 sec | 4 sec |
| Regular backlog (400 issues in backlog, 130 issues on board) | 4.8 sec | 2 sec |
| Big kanplan (8500 issues, 1500 subtasks) | 78 sec | 3.5 sec |
| Regular kanplan (320 issues in backlog, 560 issues on board) | 5 sec | 2.3 sec |
| Big sprint board (2k issues, 120 swimlanes) | 17 sec | 6.5 sec |
| Regular sprint board (130 issues) | 2.7 sec | 1.7 sec |
| Big kanban board (2k issues, 120 swimlanes) | 18.5 sec | 7 sec |
| Regular kanban board (560 issues) | 4 sec | 2.7 sec |
In the screenshots below, you can see what the Plan Mode performance was like before Jira 8.0. (Layout reflows are marked with violet background with red triangle corner.)
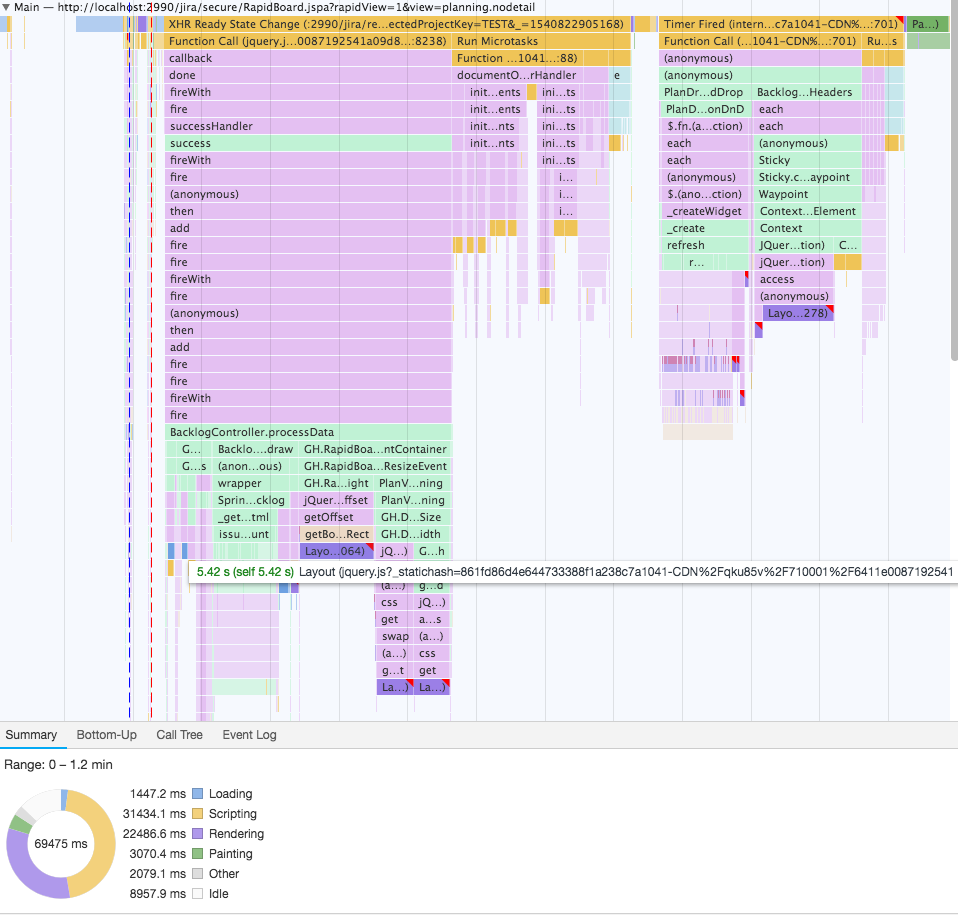
And that is what the same Plan Mode performance looks like after 8.0:
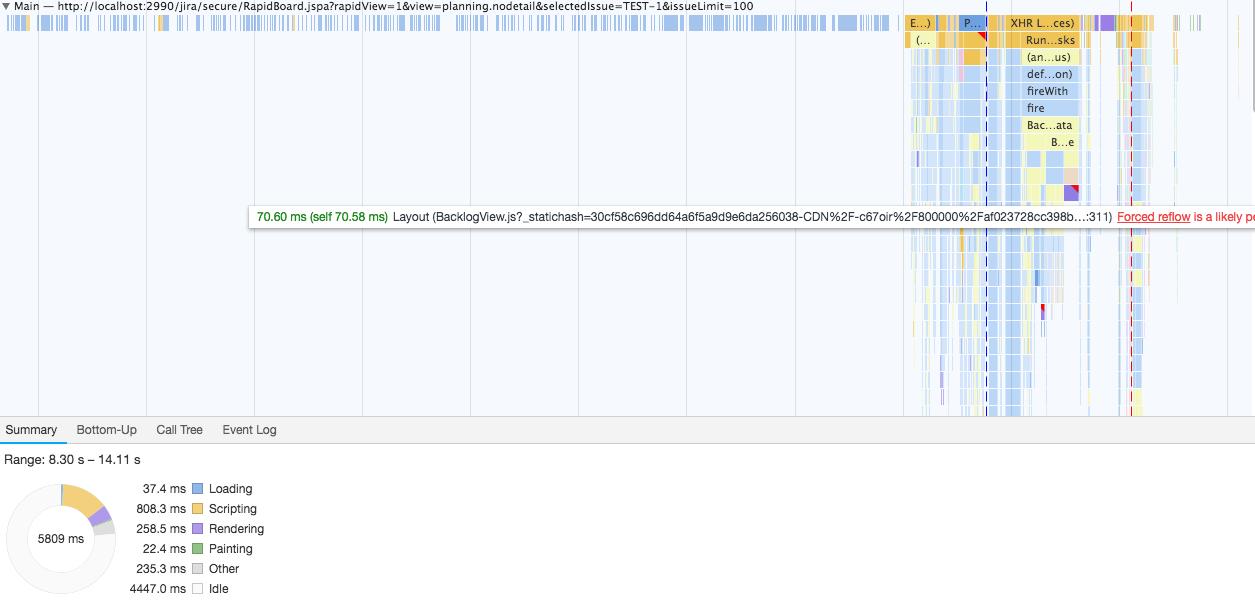
As you can see, we removed almost all reflows and optimized our functions to be faster. We also removed quadratic complexity from several functions.
If you are interested in seeing the results in your own instance, the performance chart shown on screenshots above is available from developer tools in your browser.
Chrome / Firefox: "F12" (Linux, Windows) or "CMD + ALT + I" (MacOS) →
Performance → Start recording
We hope you, the users you work with, or the customers you support will see some tangible results from these changes. Hopefully, these optimizations can also be relevant to you as you develop apps and customizations for Jira with the goal of keeping performance for users as fast as possible.
If you still have questions – feel free to ask them in Atlassian Developer Community.