Configuring a Jira cluster
Here are some ways to set up a Jira cluster using the Apache httpd server as the reverse proxy and load balancer. Also refer to Integrating Jira with Apache for a more general discussion of using Jira with Apache.
There are many load balancing and front end proxy solutions available that may suit your particular needs as well as or better than Apache httpd.
Topology
There are two options:
- Each node on a separate machine (more production-like)
- Single host configuration (easier to set up and operate for local testing)
High level guide
- Install and configure the latest Jira as normal, ie. without the cluster-specific settings mentioned further below.
-
Startup this instance and load it with your Jira test plan data.
-
Shutdown this instance.
The default HSQL database will not work with the Jira Cluster.
-
- Install a second node without launching it yet.
- Set the cluster settings on both instances as mentioned below:
- Point to the same database(the dbconfig.xml files on each should probably be identical) and an empty shared home.
- Create the cluster.properties file for each node
- Copy the following directories from the local home of the first node to the shared home (some may be empty) :
- data
- plugins
- logos
- import
- export
- Start the already-configured instance.
- Install your plugin and add the license if needed.
- Start the second instance. It will attach itself to the DB, and then fill in its local home and attach itself to the shared home. It will also then copy across your plugin.
For the clustering general release we aim to have the ability to add/update a plugin on a live cluster. This is not available yet for plugins that require upgrade tasks.
Each node on a separate machine
Each Jira node (two in this example) runs on its own machine (physical or virtual), with a third machine for the shared services. In production, the shared services will most likely run on separate machines from each other.
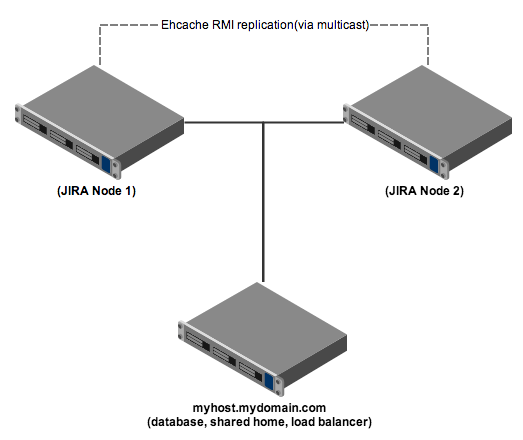
Jira setup
- On the third machine, set up a shared home directory that is writable by both servers.
- Set up the two Jira servers on different machines. These servers should:
- Have a
cluster.propertiesin the local Jira home directory (see example below). - Be configured to use the same context path.
- Be configured to use the same database. The
dbconfig.xmlfiles on each should probably be identical. - Have their Apache node name set, by appending the following setting to the same variable (replacing
node1with the node name used in the Apache load balancer configuration):-DjvmRoute=node1
- Have a
- Ensure the Base URL configured in Jira is the URL of the front end proxy / load balancer.
Example cluster.properties file
1 2# This unique ID must match the username and the BalancerMember entry in the Apache config jira.node.id = node1 # The location of the shared home directory for all Jira nodes jira.shared.home = /net/mynfsserver/jira_shared_home
httpd configuration (no context path)
We need to configure httpd similarly to a standard reverse proxy, but with the addition of the mod_proxy_balancer configuration.
To run Jira at http://MyCompanyServer/, add a configuration block similar to this at the end of http.conf.
1 2<VirtualHost *:80> ProxyRequests off ServerName MyCompanyServer <Proxy balancer://jiracluster> # Jira node 1 BalancerMember http://jira1.internal.atlassian.com:8080 route=node1 # Jira node 2 BalancerMember http://jira2.internal.atlassian.com:8080 route=node2 # Security "we aren't blocking anyone but this the place to make those changes Order Deny,Allow Deny from none Allow from all # Load Balancer Settings # We are not really balancing anything in this setup, but need to configure this ProxySet lbmethod=byrequests ProxySet stickysession=JSESSIONID </Proxy> # Here's how to enable the load balancer's management UI if desired <Location /balancer-manager> SetHandler balancer-manager # You SHOULD CHANGE THIS to only allow trusted ips to use the manager Order deny,allow Allow from all </Location> # Don't reverse-proxy requests to the management UI ProxyPass /balancer-manager ! # Reverse proxy all other requests to the Jira cluster ProxyPass / balancer://jiracluster/ ProxyPreserveHost on </VirtualHost>
httpd configuration (with a context path)
Some slight changes to the above configuration are required if Jira is deployed under a context path. To run Jira at http://MyCompanyServer/jira/, add a configuration block similar to this at the end of http.conf.
1 2<VirtualHost *:80> ProxyRequests off ServerName MyCompanyServer <Proxy balancer://jiracluster> # Jira node 1 BalancerMember http://jira1.internal.atlassian.com:8080/jira route=node1 # Jira node 2 BalancerMember http://jira2.internal.atlassian.com:8080/jira route=node2 # Security "we aren't blocking anyone but this the place to make those changes Order Deny,Allow Deny from none Allow from all # Load Balancer Settings # We are not really balancing anything in this setup, but need to configure this ProxySet lbmethod=byrequests ProxySet stickysession=JSESSIONID </Proxy> # Here's how to enable the load balancer's management UI if desired <Location /balancer-manager> SetHandler balancer-manager # You SHOULD CHANGE THIS to only allow trusted ips to use the manager Order deny,allow Allow from all </Location> # Immediately redirect /jira to /jira/ and don't pass it to the load balancer. RedirectMatch ^/jira$ /jira/ ProxyPassMatch ^/jira$ ! # Don't reverse-proxy requests to the management UI ProxyPass /balancer-manager ! # Reverse proxy all other requests to the Jira cluster ProxyPass /jira balancer://jiracluster ProxyPreserveHost on </VirtualHost>
Single host configuration
For development purposes, the entire cluster can be run on a single machine.
Configuration is as above, with the following changes:
- Each Jira node must run on different ports.
- Ehcache must be configured to use different settings; edit
the cluster.propertiesfile and add "hostName"and "port" as follows:
Sample EhCache settings for Node 1
1 2ehcache.listener.hostName=localhost ehcache.listener.port=40001 ehcache.object.port=40011
Sample EhCache settings for Node 2
1 2ehcache.listener.hostName=localhost ehcache.listener.port=40002 ehcache.object.port=40012
Trouble shooting
- Validating that caches are being replicated across the cluster correctly.
To test if caches are being replicated correctly between the two nodes in the cluster.
-
- Log in to one node in the cluster. Going directly to the node is easiest, bypassing any load balancer.
- Go to Administration / Issue Types and edit the name of an issue type
- Log in to the other node(s) in the cluster
- Go to Administration / Issue Types and check that the edited name from step-b appears correctly.
If the new value is no seen on the other nodes then the cluster is not communicating properly.
- You may need to disable your firewall, or at least allow the ports configured above to pass through. Some systems, especially later versions of linux block these even on the internal localhost network.
- You need to ensure multicast is supported. For Linux you may need to turn it on. Multicast is often not enabled for the local host.
1 2# ifconfig lo multicast # ifconfig lo lo: flags=4169<UP,LOOPBACK,RUNNING,MULTICAST> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback) RX packets 4974487 bytes 3608495877 (3.3 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 4974487 bytes 3608495877 (3.3 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- Each server needs to be able to resolve its own host name correctly. This is not as obvious as it seems and errors here can be difficult to detect
Some linux distributions will add entries to /etc/hosts such as
1 2127.0.0.1 localhost.localdomain localhost 127.0.1.1 myhost.mycompany.com myhost
This may cause ehcache to announce itself to other nodes in the cluster as being located at 127.0.1.1. This is not helpful and will result in cache inconsistency across the cluster. You can set the logging level to ehcache in log4j.properties to trace to try and diagnose this sort of error.
1 2log4j.logger.net.sf.ehcache.distribution = TRACE, console, filelog
Try removing the line refering to 127.0.1.1 from /etc/hosts or specify the hostName property for the cacheManagerPeerListenerFactory in the cluster.properties
1 2ehcache.listener.hostName=com.example.myhost
Rate this page: