Architecture overview
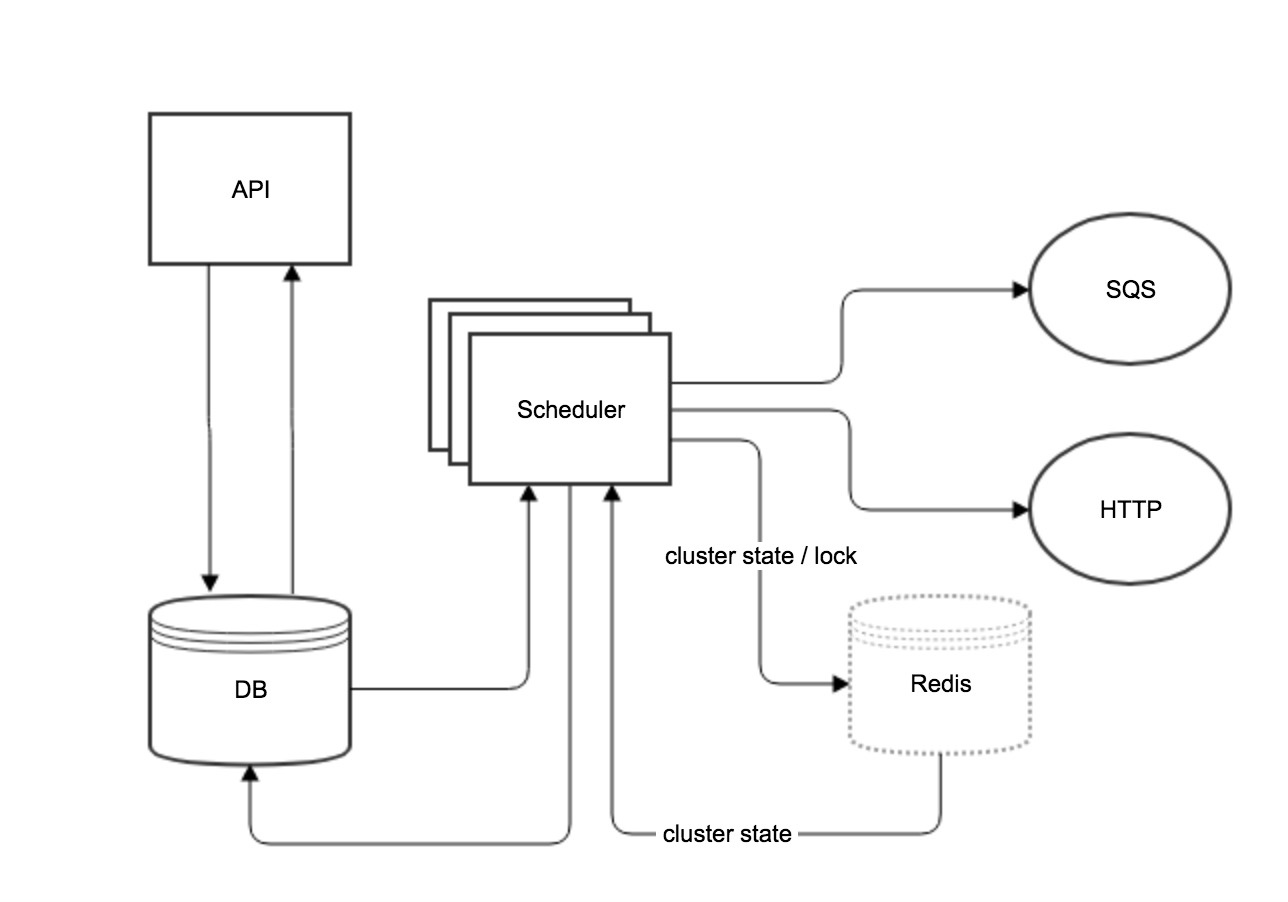
API
REST endpoints to create, update and delete jobs. Job definitions and execution history are stored in DB. Execution history is kept for a configured length of time, defaulting to 45 days.
Scheduler
A cluster of scheduler nodes each handling unique subset of managed jobs. A scheduler is responsible for executing API callbacks (SQS or HTTP) for a job when the scheduled time arrives. For jobs which repeat (Type = INTERVAL and CRON), each time a callback is completed, the scheduler also determines next callback time and schedules it.
The job ownership is determined using rendezvous hashing on the job id for the scheduler instances running in a cluster. To ensure that we do not miss a job execution, each job is scheduled on multiple schedulers. Currently the job is replicated on 2 schedulers.
When an instance of scheduler starts up, it retrieves all the jobs from the jobs table, and chooses the ones it is supposed to manage and ignores the rest.
Every few seconds, each of the schedulers looks for jobs that have been newly inserted or updated, decides if these jobs belong to its set of jobs, and updates its internal state as needed.
The instances of the scheduler keep track of which other instances exist by updating and querying the cluster state from cache. When they detect the cluster state has changed, they reload all the jobs to make sure they're managing the correct subset of the jobs.
DB
The postgres database consists of two types of tables: jobs and scheduled_jobs.
jobs table holds all the job definitions. Simplified examples in English:
- Tell A to send subscription email blah every morning at 7 am.
- Tell B that C wants to be notified that something should happen at 4:13:22 on Nov 13.
scheduled_jobs_yyyymmdd holds a record of every job run on that date. To avoid the table growing too big we use the time the job was scheduled to run to indicate which scheduled_jobs table to use.
Redis
Store and track cluster state
The cluster state is used for partitioning the nodes responsible for scheduling and executing jobs found in the database jobs table.
Each scheduler node will maintains a heartbeat activity that reports its cluster state at configured intervals. The cluster state is now stored into redis only with TTL value set to 30 seconds. The state will be expired and removed by redis after 30 seconds since it was inserted.
There are two redis shards configured for each environment. Each shard is consist of two nodes (primary and replica). Each node in one shard is located in the different availability zone from each other. Replica node syncs from primary node on best effort basis, so there can be a data lag can happen during the synchronization process. When the primary node in one shard is unavailable, redis promotes the replica in the same shard to be primary and create a new replica within the shard. When one shard is unavailable, the cluster state will be written into another shard.
Lock job execution
Since each job is owned by two schedulers, there needs to be a way that the two schedulers decide which one should run the job. This is done by competing for a lock in redis (lock key is jobId and scheduled execution time). Each scheduler tries to get the lock and the one that does is responsible for running the job and the other one works on something else. After the job execution indicating either success or failure, a row will be added to scheduled_jobs table.
redis locking has the advantage of not blocking the DB connection for the whole duration of job execution, giving scheduler the ability to execute more jobs simultaneously and relieving the pressure on db connection pool.
Rate this page: