Writing a custom importer using the JIRA importers add-on
Applicable: | This tutorial applies to JIRA 5.0.2 or later, with JIRA Importers Plugin 5.0.2 or later installed. |
Level of experience: | This is an advanced tutorial. You should have completed at least one intermediate tutorial before working through this tutorial. See the list of tutorials in DAC. |
Time estimate: | It should take you approximately 2 hours to complete this tutorial. |
Overview of this tutorial
The Atlassian JIRA Importers (JIM) add-on enables administrators to import issues from external issue trackers into JIRA. The JIM add-on is bundled with JIRA by default, but you can supplement it with your own custom importers. This lets you create importers for proprietary issue tracking systems, say, or to import issues from any type of system in some custom way.
This tutorial shows you how to create a custom importer. We'll build a plugin that imports issues from a comma-separated values file into JIRA. It's a simple example, and one that mostly duplicates an importer already in JIM, but it does show you the basic steps involved in building your own importer.
About these Instructions
You can use any supported combination of OS and IDE to create this plugin. These instructions were written using IntelliJ IDEA on Mac OS X. If you are using another OS or IDE combination, you should use the equivalent operations for your specific environment.
This tutorial was last tested with JIRA 6.0.4.
Required knowledge
To get the most out of this tutorial, you should know about:
- The basics of Java development, such as classes, interfaces, methods, and so on.
- How to create an Atlassian plugin project using the Atlassian Plugin SDK.
- How to use and administer JIRA.
Plugin source
We encourage you to work through this tutorial. If you want to skip ahead or check your work when you have finished, you can find the plugin source code on Atlassian Bitbucket. Bitbucket serves a public Git repository containing the tutorial code.
To clone the repository on your system, enter the following command:
1 2git clone https://bitbucket.org/atlassian_tutorial/tutorial-jira-simple-csv-importer.git
Alternatively, you can download the source as a ZIP archive by choosing Downloads and then Branches here: https://bitbucket.org/atlassian_tutorial/tutorial-jira-simple-csv-importer
Step 1. Create the plugin project
In this step, you'll use the atlas- command to generate stub code for your plugin. The atlas commands are part of the Atlassian Plugin SDK, and automate much of the work of plugin development for you.
-
If you haven't already set up the Atlassian Plugin SDK, do that now: Set up the Atlassian Plugin SDK and Build a Project.
-
Open a terminal and navigate to your workspace directory.
-
Enter the following command to create a plugin skeleton:
atlas-create-jira-plugin -
Choose 1 for JIRA 5 when asked which version of JIRA you want to create the plugin for.
-
As prompted, enter the following plugin settings and attributes:
group-id
com.example.plugins.tutorial.jira.csvimportartifact-id
simple-csv-importerversion
1.0-SNAPSHOTpackage
com.example.plugins.tutorial.jira.csvimport -
Confirm your entries when prompted.
The SDK creates your project home directory with initial project files, stub source code, and plugin resources.
Step 2. Modify the POM
It's a good idea to familiarize yourself with the project configuration file, known as the POM (Project Object Model definition file). Among other functions, the POM declares project dependencies and controls build settings. It also contains descriptive information for your plugin.
-
Open the POM file (
pom.xml) for editing. You can find it in the root folder of your project. -
Add your company or organization name and website to the
organizationelement:1 2
<organization> <name>Example Company</name> <url>http://www.example.com/</url> </organization> -
Next, add the following dependency and version property to your POM:
1 2
<dependencies> ... <dependency> <groupId>com.atlassian.jira.plugins</groupId> <artifactId>jira-importers-plugin</artifactId> <version>${jim.version}</version> <scope>provided</scope> </dependency> ... </dependencies> ... <properties> ... <jim.version>6.0.11</jim.version> ... </properties>Here we're adding the JIRA Importers Plugin as a dependency. Since we've set the scope of this dependency to
provided, the plugin will rely upon the JIM package that comes with JIRA at runtime. Using a different scope would likely cause classloader issues related to duplicate classes available on the plugin classpath. The JIM version we specified, 6.0.11, matches the one that comes with JIRA 6.0.4 by default. -
If you are using a version of JIRA that does not have JIM 5.0.2 or above included (JIRA versions 5.2 or earlier), you must also set the
pluginsproperty in yourpom.xml. This directs the SDK to install the specified version of JIM when starting JIRA.1 2
<properties> ... <plugins>com.atlassian.jira.plugins:jira-importers-plugin:${jim.version}</plugins> ... </properties> -
Save your changes.
Step 3. Add the external system importer module
As of JIM version 5.0, plugin developers can create importers by declaring an external-system-importer plugin module in the plugin descriptor.
Let's add one to our plugin descriptor now:
-
Open the plugin descriptor,
atlassian-plugin.xml, for editing. The plugin descriptor file is located in thesrc/main/resourcesdirectory of your project home. -
Add the
external-system-importerdeclaration as a child to theatlassian-pluginelement:1 2
<external-system-importer name="SimpleCSVImporter" key="SimpleCSVImporterKey" i18n-description-key="com.example.plugins.tutorial.jira.csvimport.description" i18n-supported-versions-key="com.example.plugins.tutorial.jira.csvimport.versions" logo-module-key="com.example.plugins.tutorial.jira.csvimport.simple-csv-importer:graphics" logo-file="simplecsv.png" class="com.example.plugins.tutorial.jira.csvimport.SimpleCsvImporterController" weight="20"/>The attributes of the element are:
keyis the plugin key for this importer.i18n-name-keyis an optional i18n key for the module name.i18n-description-keyis an i18n description string for this importer.i18n-supported-versions-keyis an optional i18n message to indicate the versions of JIRA that this importer supports.logo-module-keyis the name of the web resource containing the graphics that you want to use for this importer. This value is made up of the fully qualified plugin key for this plugin (the group ID and artifact ID you entered when creating the project), plus the name attribute from the web resource module (which we're adding in the next step).logo-fileis the name of the logo file in the web resource element defined bylogo-module-key.classis the fully qualified class name that implements interfaceAbstractImporterController. For our importer, the class will becom.example.plugins.tutorial.jira.csvimport.CsvImporterController.weightis a numeric value that determines the position of this importer in the list of external importers, with lower numbered importers appearing earlier in the list. Built-in importers have weight values of 1 to 50. Feel free to experiment with the placement of the importer on the page by modifying this number. For example, making it 0 puts it second in the list, since there's already an importer with a weight of 0.
-
Add a
web-resourceelement that identifies the graphic to be used as the icon for our custom importer in the External Importers page1 2
<web-resource key="graphics" name="Importer Graphics"> <resource type="download" name="simplecsv.png" location="images/simplecsv.png"/> </web-resource> -
Import a few external components to our plugin by adding these
component-importstatements:1 2
<component-import key="jiraDataImporter" interface="com.atlassian.jira.plugins.importer.imports.importer.JiraDataImporter"/> <component-import key="usageTrackingService" interface="com.atlassian.jira.plugins.importer.tracking.UsageTrackingService"/>This imports two components from JIM:
JiraDataImporteris responsible for handling the end-to-end import process.UsageTrackingServiceallows usage tracking of your importer. For this tutorial, we will rely upon the standard JIM tracking service. However, you can implement your own tracking just by implementing the interfaceUsageTrackingService.
Step 4. Set up a few UI resources
While in the resources directory, let's take care of a few more resources for the importer. Each importer appears on the External Importers page with an icon of about 133x64 pixels in size.
Let's add one for our importer and add UI strings:
-
Download the following image and put it in your
src/main/resources/imagesdirectory:
-
Add the following properties to the
src/main/resources/simple-csv-importer.propertiesfile.1 2
com.example.plugins.tutorial.jira.csvimport.description=Simple CSV Importer com.example.plugins.tutorial.jira.csvimport.versions=comma-separated value files com.example.plugins.tutorial.jira.csvimport.step.oauth=Authentication com.example.plugins.tutorial.jira.csvimport.step.csvSetup=Setup com.example.plugins.tutorial.jira.csvimport.step.projectMapping=Projects com.example.plugins.tutorial.jira.csvimport.step.customField=Custom Field com.example.plugins.tutorial.jira.csvimport.step.fieldMapping=Field mapping com.example.plugins.tutorial.jira.csvimport.step.valueMapping=Value mapping com.example.plugins.tutorial.jira.csvimport.step.links=Link
The description and version fields appear on the external importers page. The other fields will appear as labels for the individual steps of the import wizard.
Step 5. Implement the AbstractImporterController class
Now create the importer controller class for our plugin. This class serves as the orchestrator for the activities of our importer.
Create the importer controller class at com.example.plugins.tutorial.jira.csvimport.SimpleCsvImporterController. Give it the following code:
1 2package com.example.plugins.tutorial.jira.csvimport; import com.atlassian.jira.plugins.importer.imports.importer.ImportDataBean; import com.atlassian.jira.plugins.importer.imports.importer.JiraDataImporter; import com.atlassian.jira.plugins.importer.web.*; import com.example.plugins.tutorial.jira.csvimport.web.SimpleCsvSetupPage; import com.google.common.collect.Lists; import java.util.List; public class SimpleCsvImporterController extends AbstractImporterController { public static final String IMPORT_CONFIG_BEAN = "com.example.plugins.tutorial.jira.google.csvimport.config"; public static final String IMPORT_ID = "com.example.plugins.tutorial.jira.google.csvimport.import"; public SimpleCsvImporterController(JiraDataImporter importer) { super(importer, IMPORT_CONFIG_BEAN, IMPORT_ID); } @Override public boolean createImportProcessBean(AbstractSetupPage abstractSetupPage) { if (abstractSetupPage.invalidInput()) { return false; } final SimpleCsvSetupPage setupPage = (SimpleCsvSetupPage) abstractSetupPage; final SimpleCsvConfigBean configBean = new SimpleCsvConfigBean(new SimpleCsvClient(setupPage.getFilePath())); final ImportProcessBean importProcessBean = new ImportProcessBean(); importProcessBean.setConfigBean(configBean); storeImportProcessBeanInSession(importProcessBean); return true; } @Override public ImportDataBean createDataBean() throws Exception { final SimpleCsvConfigBean configBean = getConfigBeanFromSession(); return new SimpleCsvDataBean(configBean); } private SimpleCsvConfigBean getConfigBeanFromSession() { final ImportProcessBean importProcessBean = getImportProcessBeanFromSession(); return importProcessBean != null ? (SimpleCsvConfigBean) importProcessBean.getConfigBean() : null; } // @Override no override annotation to remain compatible with JIRA 5 public List<String> getStepNameKeys() { return Lists.newArrayList( "com.example.plugins.tutorial.jira.csvimport.step.csvSetup", "com.example.plugins.tutorial.jira.csvimport.step.projectMapping", "com.example.plugins.tutorial.jira.csvimport.step.customField", "com.example.plugins.tutorial.jira.csvimport.step.fieldMapping", "com.example.plugins.tutorial.jira.csvimport.step.valueMapping", "com.example.plugins.tutorial.jira.csvimport.step.links" ); } @Override public List<String> getSteps() { return Lists.newArrayList(SimpleCsvSetupPage.class.getSimpleName(), ImporterProjectMappingsPage.class.getSimpleName(), ImporterCustomFieldsPage.class.getSimpleName(), ImporterFieldMappingsPage.class.getSimpleName(), ImporterValueMappingsPage.class.getSimpleName(), ImporterLinksPage.class.getSimpleName()); } @Override public boolean isUsingConfiguration() { return false; } }
Notice that the import controller implements the abstract class AbstractImporterController. Included among the base methods we're overriding, we have:
-
createImportProcessBean()instantiates anImportProcessBeanandAbstractConfigBeaninstance, along with a few other things we need. The config bean in this case isSimpleCsvConfigBean, which is responsible for handling the configuration process for us. It's also responsible for storing theimportProcessBeanin the session (using the methodstoreImportProcessBeanInSession()). In our case we also createSimpleCsvClient, a helper class to encapsulate all logic connected with our external system. We must place it here, since we cannot tie custom objects toImportProcessBean; instead we'll useSimpleCsvConfigBeanto transfer this object for us. Note that storingimportProcessBeanin session means that only one importer instance may be created for each logged in user. -
createDataBean()gets help from a private method,getConfigBeanFromSession()to return the configuration data bean the controls the import process for our custom importer. -
getSteps()returns a list of action names that forms the wizard steps for this importer. Here we have:-
SimpleCsvSetupPageprovides our custom setup page that reads the file name supplied by the user. -
ImporterProjectMappingsPageis a reused project mapping page that allows the user to select or create a project into which to import the issues. -
ImporterCustomFieldsPageis a reused custom field mapping page that allows the user to map custom fields from the external issue tracker to JIRA custom fields. -
ImporterFieldMappingsPageis a reused field value mapping page that allows the user to choose how fields from the external system are mapped to JIRA issues. -
ImporterValueMappingsPageis a reused field value mapping page that allows the user to select how particular field values are mapped to JIRA issues. -
ImporterLinksPageis a reused link mapping page that allows the user to map links from external system to JIRA link types.
Note that JIM adds a final step for every importer automatically, so we didn't need to include it here. It shows the results of the import event. Also notice the .
class.getSimpleName()method call. We can call the method in this manner because, by convention, the action name is the same as the class name that implements the action. -
-
isUsingConfigBeanreturns false, which indicates that this importer will not allow customers to save configuration of the import process.
As you may surmise from our controller code, we have a few more classes to implement. Let's keep going.
Step 6. Create the SimpleCsvConfigBean class
Now create the SimpleCsvConfigBean class, com.example.plugins.tutorial.jira.csvimport.SimpleCsvConfigBean with the following code:
1 2package com.example.plugins.tutorial.jira.csvimport; import com.atlassian.jira.plugins.importer.external.beans.ExternalCustomField; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingDefinition; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingDefinitionsFactory; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingHelper; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingHelperImpl; import com.atlassian.jira.plugins.importer.imports.importer.AbstractConfigBean2; import com.example.plugins.tutorial.jira.csvimport.mapping.PriorityValueMappingDefinition; import com.google.common.collect.Lists; import java.util.List; public class SimpleCsvConfigBean extends AbstractConfigBean2 { private SimpleCsvClient csvClient; public SimpleCsvConfigBean(SimpleCsvClient csvClient) { this.csvClient = csvClient; } @Override public List<String> getExternalProjectNames() { return Lists.newArrayList("project"); } @Override public List<ExternalCustomField> getCustomFields() { return Lists.newArrayList(ExternalCustomField.createText("cf", "custom field")); } @Override public List<String> getLinkNamesFromDb() { return Lists.newArrayList("link"); } @Override public ValueMappingHelper initializeValueMappingHelper() { final ValueMappingDefinitionsFactory mappingDefinitionFactory = new ValueMappingDefinitionsFactory() { public List<ValueMappingDefinition> createMappingDefinitions(ValueMappingHelper valueMappingHelper) { final List<ValueMappingDefinition> mappings = Lists.newArrayList(); mappings.add(new PriorityValueMappingDefinition(getCsvClient(), getConstantsManager())); return mappings; } }; return new ValueMappingHelperImpl(getWorkflowSchemeManager(), getWorkflowManager(), mappingDefinitionFactory, getConstantsManager()); } public SimpleCsvClient getCsvClient() { return csvClient; } }
Our class extends AbstractConfigBean2, which is compatible with the configuration bean provided in the JIM setup pages. We must implement four abstract methods to make this configuration work:
getExternalProjectNamesreturns a list of project names in the external system. These values appear on the project mappings page, where the user can choose an external project to map to projects in JIRA. Keep in mind that for our case, external system is simply the CSV file to be imported.getCustomFieldsreturns a list of custom fields defined in the external system. You can use factory methods inExternalCustomFieldto create different types of custom fields. These custom fields appear on the custom field page, where users can choose how they'll be imported into JIRA.getLinkNamesFromDbreturns link names from the external system. The Importer Links page shows these links, and allows user to map them to JIRA link types.initializeValueMappingHelperinitializes the protected fieldvalueMappingHelper.ValueMappingHelpercontainsValueMappingDefinitionsFactory, which is responsible for creating mapping definitions. Mapping definitions associate values from the external system to issue field values in JIRA. For most cases, the importer would need to account for mappings for the Status, Issue Type, Resolution, and Priority values. But you may map any value from an issue, as listed incom.atlassian.jira.issue.IssueFieldConstants. We'll create the PriorityValueMappingDefinitionclass next.
Step 7. Create the PriorityValueMappingDefinition class
Now create the class responsible for mapping priority values from the source system to JIRA. It tells the importer which external system field is mapped to which JIRA issue field. It also defines available values in JIRA and external system for the field. Moreover it can supply default mapping between JIRA and the external system.
Create the class com.example.plugins.tutorial.jira.csvimport.mapping.PriorityValueMappingDefinition with the following code:
1 2package com.example.plugins.tutorial.jira.csvimport.mapping; import com.atlassian.jira.config.ConstantsManager; import com.atlassian.jira.issue.IssueConstant; import com.atlassian.jira.issue.IssueFieldConstants; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingDefinition; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingEntry; import com.example.plugins.tutorial.jira.csvimport.Issue; import com.example.plugins.tutorial.jira.csvimport.SimpleCsvClient; import com.google.common.base.Function; import com.google.common.collect.Collections2; import com.google.common.collect.ImmutableList; import com.google.common.collect.Iterables; import com.google.common.collect.Sets; import java.util.ArrayList; import java.util.Collection; import java.util.Set; public class PriorityValueMappingDefinition implements ValueMappingDefinition { private final SimpleCsvClient simpleCsvClient; private final ConstantsManager constantsManager; public PriorityValueMappingDefinition(SimpleCsvClient simpleCsvClient, ConstantsManager constantsManager) { this.simpleCsvClient = simpleCsvClient; this.constantsManager = constantsManager; } @Override public String getJiraFieldId() { return IssueFieldConstants.PRIORITY; } @Override public Collection<ValueMappingEntry> getTargetValues() { return new ArrayList<ValueMappingEntry>(Collections2.transform(constantsManager.getPriorityObjects(), new Function<IssueConstant, ValueMappingEntry>() { public ValueMappingEntry apply(IssueConstant from) { return new ValueMappingEntry(from.getName(), from.getId()); } })); } @Override public boolean canBeBlank() { return false; } @Override public boolean canBeCustom() { return true; } @Override public boolean canBeImportedAsIs() { return true; } @Override public String getExternalFieldId() { return "priority"; } @Override public String getDescription() { return null; } @Override public Set<String> getDistinctValues() { return Sets.newHashSet(Iterables.transform(simpleCsvClient.getInternalIssues(), new Function<Issue, String>() { @Override public String apply(Issue from) { return from.getPriority(); } })); } @Override public Collection<ValueMappingEntry> getDefaultValues() { return new ImmutableList.Builder<ValueMappingEntry>().add( new ValueMappingEntry("Low", IssueFieldConstants.TRIVIAL_PRIORITY_ID), new ValueMappingEntry("Normal", IssueFieldConstants.MINOR_PRIORITY_ID), new ValueMappingEntry("High", IssueFieldConstants.MAJOR_PRIORITY_ID), new ValueMappingEntry("Urgent", IssueFieldConstants.CRITICAL_PRIORITY_ID), new ValueMappingEntry("Immediate", IssueFieldConstants.BLOCKER_PRIORITY_ID) ).build(); } @Override public boolean isMandatory() { return false; } }
The class implements these methods:
getJiraFieldIdreturns values fromIssueFieldConstants, which determines which JIRA field this mapping relates to.getTargetValuesreturns values from JIRA for this custom field. We useconstantsManagerto obtain these values.canBeBlankif true, this field is optional in the UI.canBeCustomif true, the user can create new values in the Importer Value Mappings page. Use this option only if values for this JIRA field can be created dynamically.canBeImportedAsIsreturns true if the user does not have to provide a value for this field. In this case, the original value can be imported from the source system "as is" (that is, without further processing).getExternalFieldIdis the name of this field in the external system.getDescriptionis an optional description displayed to the user in the Importer Value Mappings page.getDistinctValuesreturns only distinct values from the external sytem.getDefaultValuesreturns the default mappings between values in the external system and in JIRA.isMandatoryshould returntrueif the user is required to map this field.
Step 8. Create the SimpleCsvDataBean class
The data bean class handles the task of transforming the imported data.
Create the class com.example.plugins.tutorial.jira.csvimport.SimpleCsvDataBean with the following code: ``
1 2package com.example.plugins.tutorial.jira.csvimport; import com.atlassian.jira.issue.IssueFieldConstants; import com.atlassian.jira.plugins.importer.external.CustomFieldConstants; import com.atlassian.jira.plugins.importer.external.beans.*; import com.atlassian.jira.plugins.importer.imports.config.ValueMappingHelper; import com.atlassian.jira.plugins.importer.imports.importer.AbstractDataBean; import com.atlassian.jira.plugins.importer.imports.importer.ImportLogger; import com.google.common.base.Function; import com.google.common.collect.Iterables; import com.google.common.collect.Lists; import com.google.common.collect.Sets; import org.apache.commons.lang.StringUtils; import java.util.*; public class SimpleCsvDataBean extends AbstractDataBean<SimpleCsvConfigBean> { private final SimpleCsvClient csvClient; private final SimpleCsvConfigBean configBean; private final ValueMappingHelper valueMappingHelper; public SimpleCsvDataBean(SimpleCsvConfigBean configBean) { super(configBean); this.configBean = configBean; this.csvClient = configBean.getCsvClient(); this.valueMappingHelper = configBean.getValueMappingHelper(); } @Override public Set<ExternalUser> getRequiredUsers(Collection<ExternalProject> projects, ImportLogger importLogger) { return getAllUsers(importLogger); } @Override public Set<ExternalUser> getAllUsers(ImportLogger log) { return Sets.newHashSet(Iterables.transform(csvClient.getInternalIssues(), new Function<Issue, ExternalUser>() { @Override public ExternalUser apply(Issue from) { return new ExternalUser(from.getAssignee(), from.getAssignee()); } })); } @Override public Set<ExternalProject> getAllProjects(ImportLogger log) { final ExternalProject project = new ExternalProject( configBean.getProjectName("project"), configBean.getProjectKey("project")); project.setExternalName("project"); return Sets.newHashSet(project); } @Override public Iterator<ExternalIssue> getIssuesIterator(ExternalProject externalProject, ImportLogger importLogger) { return Iterables.transform(csvClient.getInternalIssues(), new Function<Issue, ExternalIssue>() { @Override public ExternalIssue apply(Issue from) { final ExternalIssue externalIssue = new ExternalIssue(); final String priorityMappedValue = valueMappingHelper.getValueMapping("priority", from.getPriority()); externalIssue.setPriority(StringUtils.isBlank(priorityMappedValue) ? from.getPriority() : priorityMappedValue); externalIssue.setExternalId(from.getIssueId()); externalIssue.setSummary(from.getSummary()); externalIssue.setAssignee(from.getAssignee()); externalIssue.setExternalCustomFieldValues(Lists.newArrayList( new ExternalCustomFieldValue(configBean.getFieldMapping("cf"), CustomFieldConstants.TEXT_FIELD_TYPE, CustomFieldConstants.TEXT_FIELD_SEARCHER, from.getCustomField()))); externalIssue.setStatus(String.valueOf(IssueFieldConstants.OPEN_STATUS_ID)); externalIssue.setIssueType(IssueFieldConstants.BUG_TYPE); return externalIssue; } }).iterator(); } @Override public Collection<ExternalLink> getLinks(ImportLogger log) { final List<ExternalLink> externalLinks = Lists.newArrayList(); final String linkName = configBean.getLinkMapping("link"); for (Issue issue : csvClient.getInternalIssues()) { if (StringUtils.isNotBlank(issue.getLinkedIssueId())) { externalLinks.add(new ExternalLink(linkName, issue.getIssueId(), issue.getLinkedIssueId())); } } return externalLinks; } @Override public long getTotalIssues(Set<ExternalProject> selectedProjects, ImportLogger log) { return csvClient.getInternalIssues().size(); } @Override public String getUnusedUsersGroup() { return "simple_csv_import_unused"; } @Override public void cleanUp() { } @Override public String getIssueKeyRegex() { return null; } @Override public Collection<ExternalVersion> getVersions(ExternalProject externalProject, ImportLogger importLogger) { return Collections.emptyList(); } @Override public Collection<ExternalComponent> getComponents(ExternalProject externalProject, ImportLogger importLogger) { return Collections.emptyList(); } }
The class extends AbstractDataBean<SimpleCsvConfigBean>, a helper class that combines our config bean and allows using user mapped values for projects and issues. We must implement these methods to make our data bean work:
-
getRequiredUsersreturns the user accounts that are effectively used in the JIRA project targeted for the import. In our case we just return all users, as we use all of them. -
getAllUsersreturns the users from the external system. -
getAllProjectsreturns all projects from the external system. In our case we return one project. Notice that we useconfigBean.getProjectName(``"project"``) and configBean.getProjectKey(``"project") to get values defined by the user for the project named "project", as specified on the Importer Project Mappings page. -
getIssuesIteratorreturns an iterator with all issues in the external project. In this method importer is responsible for mapping custom fields and values to ones selected by the user.
Notice the following points:-
We use
valueMappingHelper.getValueMapping(``"priority"``, from.getPriority())to get the priority value that the user selected. The "priority" string is the name of the external system field defined in ourPriorityValueMappingDefinitionclass. Because we decided that the user can use each value "as is," we must check whether the user has provided a value for this mapped value. If not, we must use the original value from the external system. -
We use
configBean.getFieldMapping(``"cf"``)to get the user-selected name for custom field. We use the same id "cf" that was defined inSimpleCsvConfigBean#getCustomFields.
-
-
getLinksreturns all links between issues in the external system. TheconfigBean.getLinkMapping(``"link"``)call gets the name of the link that the user has selected, passed as the "link" parameter, and which is defined inSimpleCsvConfigBean#getLinkNamesFromDb. -
getTotalIssuesreturns all issues for the selected projects. -
getUnusedUsersGroupreturns JIRA group that will be created for users that are not active. -
cleanUpis called after the import has finished. You can clean up used resources here. -
getIssueKeyRegexcan return a regular expression that matches on external system issue keys. Matched expressions in summary, comments, and description fields are replaced by the assigned JIRA issue key. For example, ("case: 2842") will be rewritten to JIRA references ("JRA-2848"). -
getVersionsreturns all versions for the given project. In our example we do not handle versions, so we just return an empty collection. -
getComponentsreturns all components for given project. In our example we do not handle components, so we just return an empty collection.
Step 9. Define the CSV file text field as a webwork action
The first page of the import page sequence is the setup page. It gets the path to the CSV file that contains the data we need to import. For simplicity, we'll require the user to specify the file by path on the local file system, leaving file upload outside the scope of this tutorial.
Our setup page is composed by several parts: the class that implements the setup page, a Velocity template, and the descriptor module that ties them together. We'll start with the class:
-
Create the class
com.example.plugins.tutorial.jira.csvimport.web.SimpleCsvSetupPagewith the following content1 2
package com.example.plugins.tutorial.jira.csvimport.web; import com.atlassian.jira.plugins.importer.extensions.ImporterController; import com.atlassian.jira.plugins.importer.tracking.UsageTrackingService; import com.atlassian.jira.plugins.importer.web.AbstractSetupPage; import com.atlassian.jira.plugins.importer.web.ConfigFileHandler; import com.atlassian.jira.security.xsrf.RequiresXsrfCheck; import com.atlassian.plugin.PluginAccessor; import com.atlassian.plugin.web.WebInterfaceManager; import com.example.plugins.tutorial.jira.csvimport.SimpleCsvClient; public class SimpleCsvSetupPage extends AbstractSetupPage { private String filePath; public SimpleCsvSetupPage(UsageTrackingService usageTrackingService, WebInterfaceManager webInterfaceManager, PluginAccessor pluginAccessor) { super(usageTrackingService, webInterfaceManager, pluginAccessor); } @Override public String doDefault() throws Exception { if (!isAdministrator()) { return "denied"; } final ImporterController controller = getController(); if (controller == null) { return RESTART_NEEDED; } return INPUT; } @Override @RequiresXsrfCheck protected String doExecute() throws Exception { final ImporterController controller = getController(); if (controller == null) { return RESTART_NEEDED; } if (!isPreviousClicked() && !controller.createImportProcessBean(this)) { return INPUT; } return super.doExecute(); } @Override protected void doValidation() { if (isPreviousClicked()) { return; } try { new SimpleCsvClient(filePath); } catch (RuntimeException e) { addError("filePath", e.getMessage()); } super.doValidation(); } public String getFilePath() { return filePath; } public void setFilePath(String filePath) { this.filePath = filePath; } }Notice a few things:
- The
@RequiresXsrfCheckannotation for thedoExecutemethod is important! If not present, the user does not need to provide admin credentials to change JIRA state, which would create a serious security hole in the JIRA instance. Be sure to add it to your own importer implementations. - To validate input,
doValidation()simply attempts to instantiateSimpleCsvClientto see whether the provided file path is valid.
- The
-
Back in the descriptor file,
atlassian-plugin.xml, add the following webwork action module:1 2
<webwork1 key="actions" name="Actions"> <actions> <action name="com.example.plugins.tutorial.jira.csvimport.web.SimpleCsvSetupPage" alias="SimpleCsvSetupPage"> <view name="input">templates/csvSetupPage.vm</view> <view name="denied">/secure/views/securitybreach.jsp</view> <view name="restartimporterneeded">/templates/admin/views/restartneeded.vm</view> </action> </actions> </webwork1>The module references the setup page class you just added, and the Velocity template that will display our form. It's important for the
aliasattribute value to be the name of the class that implements the action. Notice also that we reuse page resources from JIRA:restartneeded.vm, from JIM plugin, displays information indicating to the user that the import process needs to be restarted. This appears if the user tries to omit steps in the setup wizard, or for any reason the HTTP session ends.securitybreach.jsp, from JIRA core, displays information about unauthorized usage.
-
Create the Velocity template for our setup page by adding the following code to a file named
csvSetupPage.vmin a new directory,src/main/resources/templates:1 2
#parse('/templates/admin/views/common/import-header.vm') #set ($auiparams = $map.build('name', 'filePath', 'label', "CSV File path", 'size', 60, 'value', $action.filePath, 'required', true)) #parse("/templates/standard/textfield.vm") #parse("/templates/admin/views/common/standardSetupFooter.vm")This is the page that lets the user enter the path to the CSV file they want to import. In it, we use JIM-provided templates to format our page:
-
import-header.vmadds a standard header for all JIRA importers. -
textfield.vmrenders simple HTML input with type text and parameters provided in theauiparamsvariable. -
standardSetupFooter.vmputs Next and Back buttons on the page, along with the standard footer.
-
Step 10. Create the SimpleCsvClient class and data model
Finally, let's create a class that simulates our external issue tracker and models the data in our external issue tracking system. That data will be in CSV files and consist of six fields separated by a comma. The fields are issueId, summary, priority, assignee, customField, and inkedIssueId.
Create com.example.plugins.tutorial.jira.csvimport.SimpleCsvClient to simulate our external issue tracker:
SimpleCsvClient
1 2package com.example.plugins.tutorial.jira.csvimport; import com.google.common.base.Splitter; import com.google.common.collect.Lists; import org.apache.commons.io.IOUtils; import java.io.FileInputStream; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * we assume data is in constant format * issueId,summary, priority, assignee, customField,linkedIssueId */ public class SimpleCsvClient { private List<Issue> internalIssues; public List<Issue> getInternalIssues() { return internalIssues; } public SimpleCsvClient(String filePath) { try { final FileInputStream input = new FileInputStream(filePath); try { final List<String> content = IOUtils.readLines(input); internalIssues = Lists.newArrayListWithExpectedSize(content.size()); final Splitter splitter = Splitter.on(",").trimResults(); for (int i = 0, contentSize = content.size(); i < contentSize; i++) { final String issueLine = content.get(i); final ArrayList<String> values = Lists.newArrayList(splitter.split(issueLine)); if (values.size() != 6) { throw new RuntimeException("Invalid line " + (i + 1) + " " + issueLine + " should contain six values"); } internalIssues.add(new Issue(values)); } } finally { input.close(); } } catch (IOException e) { throw new RuntimeException(e); } } }
Not much of interest here. The main point to know for now is that SimpleCsvClient is capable of returning a list of issues containing six values: issueId, summary, priority, assignee, customField, linkedIssueId.
Now create the issue class, com.example.plugins.tutorial.jira.csvimport.Issue:
1 2package com.example.plugins.tutorial.jira.csvimport; import java.util.List; /** * Helper class to convert issues from csv values */ public class Issue { private final String issueId; private final String summary; private final String priority; private final String assignee; private final String customField; private final String linkedIssueId; public Issue(List<String> values) { issueId = values.get(0); summary = values.get(1); priority = values.get(2); assignee = values.get(3); customField = values.get(4); linkedIssueId = values.get(5); } public String getIssueId() { return issueId; } public String getSummary() { return summary; } public String getPriority() { return priority; } public String getAssignee() { return assignee; } public String getCustomField() { return customField; } public String getLinkedIssueId() { return linkedIssueId; } }
Create data for our external system. Add the following data to a file named test.csv in the test/resources folder:
1 21,summary 1,Low,user1,value1,2 2,summary 2,High,user1,value2,3 3,summary 3,Low,user2,value1, 4,summary 4,Unknown,user3,value3,
The same file is checked into the tutorial repository on Bitbucket. The filename and location (test/resources/test.csv) isn't so important for now; users of the importer can specify the file anywhere in the setup page. But it is where the integration test that we'll build later expects the test data to be, so putting it there now saves a step for later.
We're ready to start JIRA and see what we've got so far.
Step 11. Start JIRA and try out the importer
Follow these steps to install and test the importer plugin:
-
In a terminal window, navigate to the plugin root folder (where the
pom.xmlfile is) and runatlas-run(oratlas-debugif you might want to launch the debugger in your IDE).
JIRA takes a few minutes to download and start up. -
When JIRA finishes starting up, open the JIRA home page in a browser. JIRA prints the URL to use in the console output.
-
Log in with the default user and password combination, admin/admin.
-
Create a new project based on the Software Development Template. You'll need this because it has the issue states that our plugin depends upon (such as the open state).
-
From the JIRA header, click Projects > Import External Project.
-
Find your importer in the list. As you may recognize, it's the one named Simple CSV Importer:

-
Click on the importer to launch the wizard. You should see the first step in the wizard, the setup page you created:
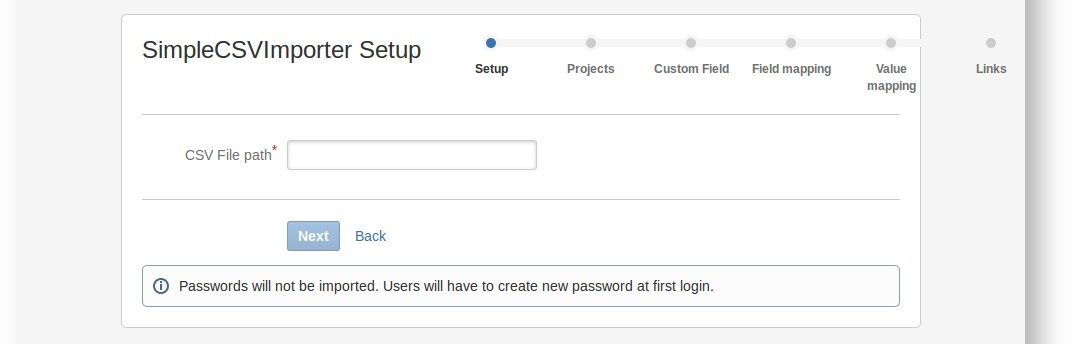
-
In the CSV File path field, enter the path to the file and click Next. For example:
//home/atlas/atlassian/tutorial-jira-simple-csv-importer/src/test/resources/test.csv -
Continue working through the wizard. In step 2, be sure to map the imported issues to the software development project you created.
-
Finally, click the Begin Import button to finish the import.
When done, you should get a message similar to this one: 0 projects and 4 issues imported successfully! If you navigate to the project, you should see four new issues in your project.
Let's extend the importer a bit by allowing users to save the configuration they've used to perform an import. They can then use the same configuration to quickly perform more imports.
At this point you can leave JIRA running and use FastDev or the atlas-cli and pi commands to reinstall your plugin without having to restart JIRA.
Step 12. Expand the plugin to support configuration files
So far you have a basic importer that can import simple CSV files. Let's extend it a bit to provide the ability to save configuration settings to a file. The administrator can then reuse the configuration on subsequent imports. This comes in handy when you need to import many projects with the same import settings.
-
Add component import to
atlassian-plugin.xml. This will import ConfigFileHandler which will help us handle serialization and desalinization of importer configuration.1 2
<component-import key="configFileHandler" interface="com.atlassian.jira.plugins.importer.web.ConfigFileHandler"/> -
Extend the
SimpleCsvSetupPageclass as follows:-
Add a constructor parameter and field for
ConfigFileHandler:1 2
... private final ConfigFileHandler configFileHandler; public SimpleCsvSetupPage(UsageTrackingService usageTrackingService, WebInterfaceManager webInterfaceManager, PluginAccessor pluginAccessor, ConfigFileHandler configFileHandler) { super(usageTrackingService, webInterfaceManager, pluginAccessor); this.configFileHandler = configFileHandler; } ...This allows us to use
configFileHandlerto validate the configuration file provided by the user. -
Add this validation code as the last line of the
doValidationmethod ofSimpleCsvSetupPage:1 2
... protected void doValidation() { ... configFileHandler.verifyConfigFileParam(this); }Expand the following code block to see what the entire class should now look like:
1 2
package com.example.plugins.tutorial.jira.csvimport.web; import com.atlassian.jira.plugins.importer.extensions.ImporterController; import com.atlassian.jira.plugins.importer.tracking.UsageTrackingService; import com.atlassian.jira.plugins.importer.web.AbstractSetupPage; import com.atlassian.jira.plugins.importer.web.ConfigFileHandler; import com.atlassian.jira.security.xsrf.RequiresXsrfCheck; import com.atlassian.plugin.PluginAccessor; import com.atlassian.plugin.web.WebInterfaceManager; import com.example.plugins.tutorial.jira.csvimport.SimpleCsvClient; public class SimpleCsvSetupPage extends AbstractSetupPage { private String filePath; private final ConfigFileHandler configFileHandler; public SimpleCsvSetupPage(UsageTrackingService usageTrackingService, WebInterfaceManager webInterfaceManager, PluginAccessor pluginAccessor, ConfigFileHandler configFileHandler) { super(usageTrackingService, webInterfaceManager, pluginAccessor); this.configFileHandler = configFileHandler; } @Override public String doDefault() throws Exception { if (!isAdministrator()) { return "denied"; } final ImporterController controller = getController(); if (controller == null) { return RESTART_NEEDED; } return INPUT; } @Override @RequiresXsrfCheck protected String doExecute() throws Exception { final ImporterController controller = getController(); if (controller == null) { return RESTART_NEEDED; } if (!isPreviousClicked() && !controller.createImportProcessBean(this)) { return INPUT; } return super.doExecute(); } @Override protected void doValidation() { if (isPreviousClicked()) { return; } try { new SimpleCsvClient(filePath); } catch (RuntimeException e) { addError("filePath", e.getMessage()); } super.doValidation(); configFileHandler.verifyConfigFileParam(this); } public String getFilePath() { return filePath; } public void setFilePath(String filePath) { this.filePath = filePath; } }
-
-
Now extend the
SimpleCsvImporterControllerclass as follows:-
First add constructor parameter and field for
ConfigFileHandler.1 2
... private final ConfigFileHandler configFileHandler; public SimpleCsvImporterController(JiraDataImporter importer, ConfigFileHandler configFileHandler) { super(importer, IMPORT_CONFIG_BEAN, IMPORT_ID); this.configFileHandler = configFileHandler; } ... -
Populate the configuration file in
createImportProcessBeanmethod ofSimpleCsvImporterController, as follows:1 2
public boolean createImportProcessBean(AbstractSetupPage abstractSetupPage) { ... final SimpleCsvConfigBean configBean = new SimpleCsvConfigBean(new SimpleCsvClient(setupPage.getFilePath())); final ImportProcessBean importProcessBean = new ImportProcessBean(); if (!configFileHandler.populateFromConfigFile(setupPage, configBean)) { return false; } importProcessBean.setConfigBean(configBean); ... } -
Finally remove the
isUsingConfigurationmethod. By default (i.e., if not overridden), this method returnstrue, which is what we want to do now that we support saving the configuration.
-
-
Extend your setup page Velocity template,
csvSetupPage.vm, to allow users to provide a configuration file for the import settings. To do this simply add this parse directive to yourcsvSetupPage.vmfile before thestandardSetupFooter.vmdirective:1 2
#parse('/templates/admin/views/common/configFile.vm')
Step 13. Try it again
Reload the plugin in JIRA and try your custom importer again. Now you should see a new option on the first page of the wizard, a checkbox for Use an existing configuration file:

We don't have a configuration file yet, so proceed through the wizard manually, as before.
And after completing import process you should see something like this:

Notice the new sentence in the What now? information. The save the configuration link lets you save the configuration as a file and reuse it to perform the next import. Give it a shot!
Step 14. Create integration tests
To round out the picture, let's add a couple integration tests for our plugin. Writing unit tests is beyond the scope of this tutorial. Instead, we'll describe how to write an integration test that uses web driver and JIRA page objects. You will learn how to write your own page objects and how to use them to simulate user behavior to test the simple CSV importer.
You'll notice that the SDK generated some test code for us. Those tests are intended to serve as the starting point for tests. We'll use the test directory it created for the following additional tests.
-
Update your
pom.xmlwith some dependencies required for the tests:1 2
<dependency> <groupId>com.atlassian.jira</groupId> <artifactId>atlassian-jira-pageobjects</artifactId> <version>${jira.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>com.atlassian.jira.plugins</groupId> <artifactId>jira-importers-plugin</artifactId> <version>${jim.version}</version> <classifier>tests</classifier> <scope>test</scope> </dependency> <dependency> <groupId>com.atlassian.jira.tests</groupId> <artifactId>jira-testkit-client</artifactId> <version>${testkit.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-core-asl</artifactId> <version>1.9.1</version> </dependency> <dependency> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-xc</artifactId> <version>1.9.1</version> </dependency> <dependency> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-jaxrs</artifactId> <version>1.9.1</version> </dependency> <dependency> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-mapper-asl</artifactId> <version>1.9.1</version> </dependency> -
Also in the POM, add a
pluginsproperty to include the JIRA testkit plugin:1 2
<properties> ... <testkit.version>5.0-m13</testkit.version> <plugins>com.atlassian.jira.plugins:jira-importers-plugin:${jim.version},com.atlassian.jira.tests:jira-testkit-plugin:${testkit.version}</plugins> </properties>This means that when the SDK starts, JIRA will include the JIRA testkit plugin, enabling us to change the state of JIRA using the backdoor plugin.
-
Create the page object that represents
SImpleCsvSetupPage. Under the test directory (src/test/) create the classcom.example.plugins.jira.csvimport.po.SimpleCsvSetupPage, with the following contents:1 2
package com.example.plugins.jira.csvimport.po; import com.atlassian.jira.plugins.importer.po.common.AbstractImporterWizardPage; import com.atlassian.jira.plugins.importer.po.common.ImporterProjectsMappingsPage; import org.junit.Assert; import org.openqa.selenium.WebElement; import org.openqa.selenium.support.FindBy; public class SimpleCsvSetupPage extends AbstractImporterWizardPage { @FindBy(id = "filePath") WebElement filePath; public SimpleCsvSetupPage setFilePath(String filePath) { this.filePath.sendKeys(filePath); return this; } @Override public String getUrl() { return "/secure/admin/views/SimpleCsvSetupPage!default.jspa?externalSystem=" + "com.example.plugins.tutorial.jira.simple-csv-importer:SimpleCSVImporterKey"; } public ImporterProjectsMappingsPage next() { Assert.assertTrue(nextButton.isEnabled()); nextButton.click(); return pageBinder.bind(ImporterProjectsMappingsPage.class); } } -
Still in the tests directory, create a test class
it.com.example.plugins.jira.csvimport.TestSimpleCsvImporter.1 2
package it.com.example.plugins.jira.csvimport; import com.atlassian.jira.pageobjects.JiraTestedProduct; import com.atlassian.jira.pageobjects.config.EnvironmentBasedProductInstance; import com.atlassian.jira.plugins.importer.po.ExternalImportPage; import com.atlassian.jira.plugins.importer.po.common.ImporterLinksPage; import com.atlassian.jira.plugins.importer.po.common.ImporterProjectsMappingsPage; import com.atlassian.jira.testkit.client.Backdoor; import com.atlassian.jira.testkit.client.restclient.SearchRequest; import com.atlassian.jira.testkit.client.restclient.SearchResult; import com.atlassian.jira.testkit.client.util.TestKitLocalEnvironmentData; import com.example.plugins.jira.csvimport.po.SimpleCsvSetupPage; import org.junit.Before; import org.junit.Test; import static org.junit.Assert.*; import static org.junit.matchers.JUnitMatchers.hasItem; public class TestSimpleCsvImporter { private JiraTestedProduct jira; private Backdoor backdoor; @Before public void setUp() { backdoor = new Backdoor(new TestKitLocalEnvironmentData()); backdoor.restoreBlankInstance(); jira = new JiraTestedProduct(null, new EnvironmentBasedProductInstance()); } @Test public void testSimpleCsvImporterAttachedToConfigPage() { assertThat(jira.gotoLoginPage().loginAsSysAdmin(ExternalImportPage.class).getImportersOrder(), hasItem("SimpleCSVImporter")); } @Test public void testSimpleCsvImporterWizard() { backdoor.issueLinking().enable(); backdoor.issueLinking().createIssueLinkType("Related", "related", "related to"); final SimpleCsvSetupPage setupPage = jira.gotoLoginPage().loginAsSysAdmin(SimpleCsvSetupPage.class); final String file = getClass().getResource("/test.csv").getFile(); final ImporterProjectsMappingsPage projectsPage = setupPage.setFilePath(file).next(); projectsPage.createProject("project", "JIRA Project", "PRJ"); final ImporterLinksPage linksPage = projectsPage.next().next().next().next(); linksPage.setSelect("link", "Related"); assertTrue(linksPage.next().waitUntilFinished().isSuccess()); final SearchResult search = backdoor.search().getSearch(new SearchRequest().jql("")); assertEquals((Integer) 4, search.total); } }Note that the package name for this or any integration test class must start with
it. The SDK run environment looks for integration tests there. Notice the following about our test class:-
First, we use the
setUpmethod to create the backdoor client used to restore JIRA to an empty state. -
The first of our two tests checks whether our importer is added to the External Import page.
-
The second test goes through our Simple CSV Importer wizard and uses the backdoor to make sure that four issues have been created.
-
-
The test depends on your CSV file being in a particular location. If you don't already have your test data at the expected location, put the following test data at
test/resources/test.csv:1 2
1,summary 1,Low,user1,value1,2 2,summary 2,High,user1,value2,3 3,summary 3,Low,user2,value1, 4,summary 4,Unknown,user3,value3, -
You also need to create a directory,
test/xml, for the tests to use. It can be empty. -
Now you're ready to run the test! In the console, enter the command
atlas-integration-test.
This starts JIRA, opens a Firefox browser, and runs the tests. For details of the results, inspect the log files at the location indicated in the command terminal output.
Rate this page: